






 BTC/HKD+3.18%
BTC/HKD+3.18% ETH/HKD+5.58%
ETH/HKD+5.58% LTC/HKD+1.95%
LTC/HKD+1.95% DOT/HKD+5.25%
DOT/HKD+5.25% ADA/HKD+6.08%
ADA/HKD+6.08% SOL/HKD+4.35%
SOL/HKD+4.35% XRP/HKD+3.61%
XRP/HKD+3.61% DOGE/US+5.95%
DOGE/US+5.95%作者:@於方仁@CarolineSun
編排:@黑羽小斗
LLM
大型語言模型是利用海量的文本數據進行訓練海量的模型參數。大語言模型的使用,大體可以分為兩個方向:
A.僅使用
B.微調后使用
僅使用又稱Zero-shot,因為大語言模型具備大量通用的語料信息,量變可以產生質變。即使Zero-shot也許沒得到用戶想要的結果,但加上合適的prompt則可以進一步獲取想要的知識。該基礎目前被總結為promptlearning。
大語言模型,比較流行的就是BERT和GPT。從生態上講BERT與GPT最大的區別就是前者模型開源,后者只開源了調用API,也就是目前的ChatGPT。
兩個模型均是由若干層的Transformer組成,參數數量等信息如下表所示。
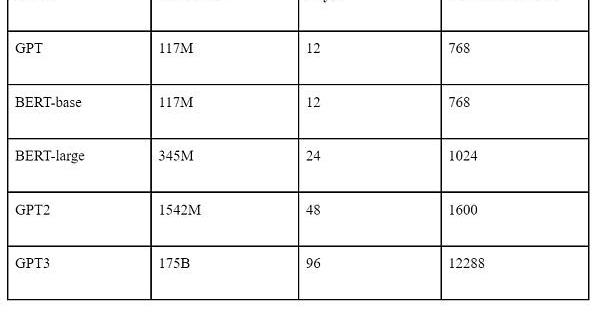
目前生態上講,BERT多用于微調場景。因為微調必須在開源模型的基礎上,GPT僅開源到GPT2的系列。且相同模型參數量下BERT在特定場景的效果往往高于GPT,微調需要調整全部的模型參數,所以從性價比而言,BERT比GPT更適合微調。
而GPT目前擁有ChatGPT這種面向廣大人民群眾的應用,使用簡單。API的調用也尤其方便。所以若是僅使用LLM,則ChatGPT顯然更有優勢。
ChatGPTPrompt
Base與Backdrop推出100 Builders,幫助開發者在Base上構建開源技術:金色財經報道,Base宣布與Backdrop合作推出100 Builders,旨在幫助更多人在Base上構建開源,創造更多更好的開源技術,該計劃對構建者免費,建設者可獲得超過 4 萬美元的獎金,申請截止日期為 2023 年 8 月 10 日,計劃啟動日期為 2023 年 8 月 21 日。[2023/8/9 21:33:04]
下圖是OpenAI官方提出對于ChatGPT的prompt用法大類。
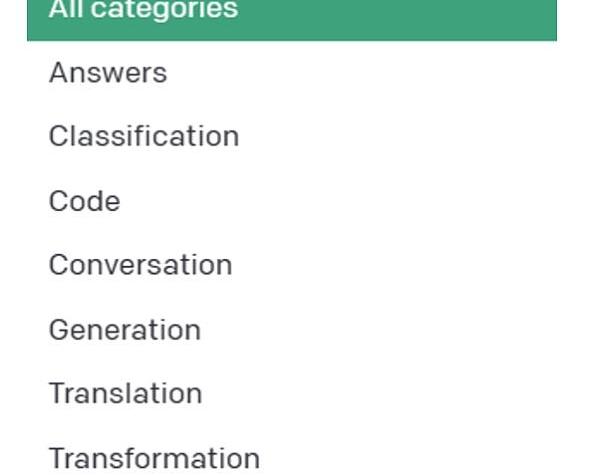
Figure1.PromptCategoriesbyOpenAI?
每種類別有很多具體的范例。如下圖所示:
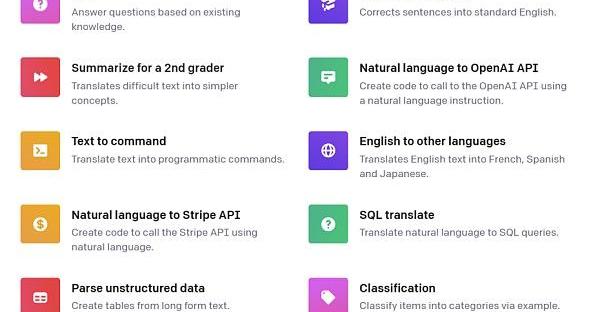
Figure2.PromptCategoriesExamplesbyOpenAI
除此以外,我們在此提出一些略微高級的用法。
高級分類
這是一個意圖識別的例子,本質上也是分類任務,我們指定了類別,讓ChatGPT判斷用戶的意圖在這
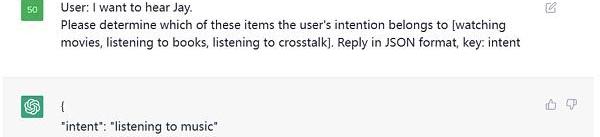
Klaytn公布BUIDL the Future黑客松Klaytn賽道獲獎項目:3月2日消息,韓國區塊鏈平臺Klaytn發文介紹Coinbase Cloud主辦的BUIDL the Future黑客松Klaytn賽道的獲獎項目者,分別為:冠軍項目Web3眾籌平臺Wanna、第一名NFT游戲化平臺 Encryp、第二名NFT資產管理平臺 GameFolio。[2023/3/2 12:38:36]
Figure3.PromptExamples
實體識別與關系抽取
利用ChatGPT做實體識別與關系抽取輕而易舉,例如給定一篇文本后,這么像它提問。
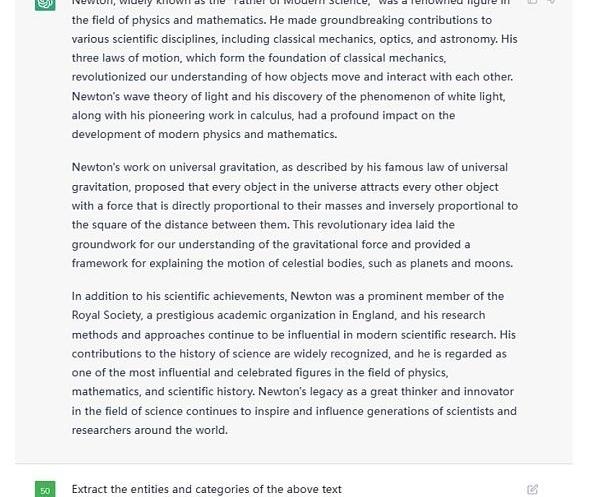
Figure4.ExampleTextGiventoChatGPT
這是部分結果截圖:
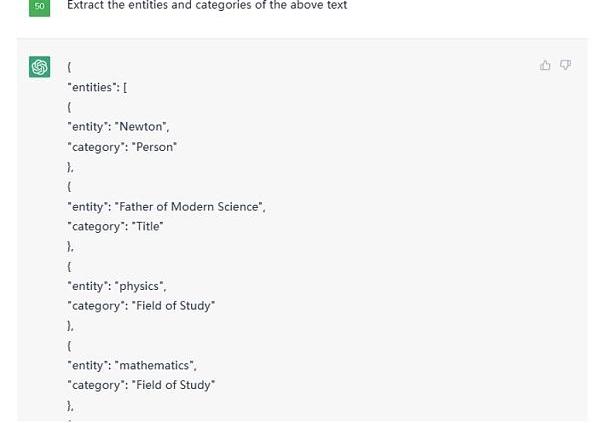
Figure5.PartialOutputfromgivenTextonChatGPT
之后可以追問給他們的關系,例如:

Figure6.AskingrelationshiponChatGPT
孫宇晨受邀參加第13屆金融科技峰會“Building Tomorrow’s Marketplaces”:據官方消息,波場TRON創始人兼BitTorrent CEO孫宇晨受邀參加投資銀行集團Rosenblatt Securities舉辦的第13屆金融科技峰會“Building Tomorrow’s Marketplaces”,并將于5月19日12:00 pm—1:00 pm EDT(北美東部夏令時間)進行“市場的未來發展”主題討論。據悉,本次大會將于2021年5月19日-5月20日EDT (北美東部夏令時間)舉行,共有包括孫宇晨、納斯達克 CEO 阿德娜·弗里德曼(Adena Friedman)等16位尖端金融科技思想領袖共同出席。Rosenblatt金融科技峰會已經連續舉辦了13年,匯聚了金融科技首席執行官,以描述他們如何幫助金融服務業轉型。[2021/5/10 21:44:07]
這樣,一個大型的知識圖譜便可輕松建立。
分析任務
如下圖所示,我對ChatGPT提出了分析我目前需求的問題。
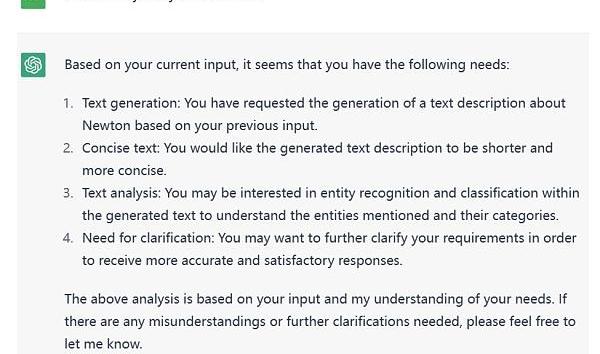
Figure7.ResultforneedsrequestonChatGPT
甚至還能讓它給定分數。

幣贏CoinW將于8月4日17:00在潛力區上線BUIDL:據官方消息,幣贏CoinW將于8月4日17:00在潛力區上線BUIDL,開通BUIDL/USDT交易對,同時開啟“充值送BUIDL,Maker-0.1%費率”活動;據悉,Buidl是DFOhub的治理代幣。DFOhub是一個基于DFO協議的獨立的去中心化組織,通過BUIDLToken持有者擁有協議及其資產的所有權。[2020/8/4]
Figure8.Scoringtoevaluatetheidentifiedneeds
除此以外還有數不勝數的方式,在此不一一列舉。
組合Agent
另外,我們在使用ChatGPT的API時,可以將不同的prompt模板產生多次調用產生組合使用的效果。我愿稱這種使用方式叫做,組合Agent。例如Figure1展示的是一個大概的思路。
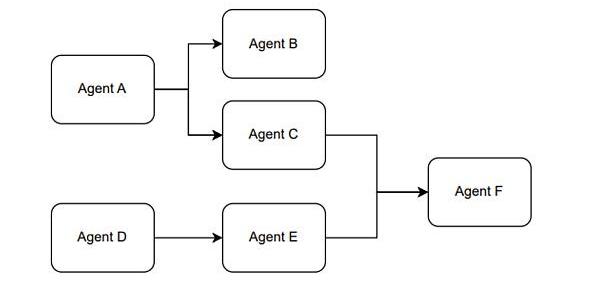
Figure9.?TheParadigmoftheCombinationAgent
具體說來,例如是一個輔助創作文章的產品。則可以這么設計,如Figure10所示。
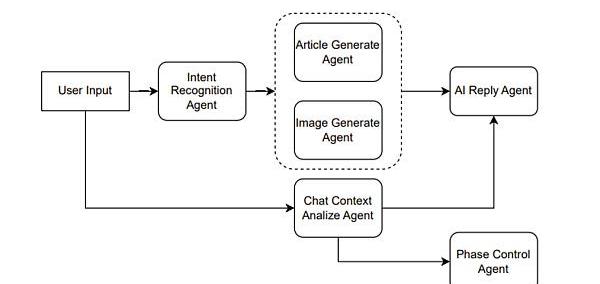
Figure10.Agentcombinationforassistingincreation
動態 | 質押流動性協議Stafi加入Substrate Builders計劃:金色財經報道,為質押資產提供流動性的去中心化協議Stafi今天宣布成為Substrate Builders計劃成員。該項目的背后組織Parity希望為Substrate Builders創造一個空間來解決項目的獨特問題和需求。從目前的開發情況來看,Stafi的開發進展順利,即將進入公共測試網階段。[2020/2/25]
假設用戶輸入一個請求,說“幫我寫一篇倫敦游記”,那么IntentRecognitionAgent首先做一個意圖識別,意圖識別也就是利用ChatGPT做一次分類任務。假設識別出用戶的意圖是文章生成,則接著調用ArticleGenerateAgent。
另一方面,用戶當前的輸入與歷史的輸入可以組成一個上下文,輸入給ChatContextAnalyzeAgent。當前例子中,這個agent分析出的結果傳入后面的AIReplyAgent和PhaseControlAgent的。
AIReplyAgent就是用來生成AI回復用戶的語句,假設我們的產品前端并不只有一個文章,另一個敵方還有一個框用來顯示AI引導用戶創作文章的語句,則這個AIReplyAgent就是用來干這個事情。將上下文的分析與文章一同提交給ChatGPT,讓其根據分析結果結合文章生成一個合適的回復。例如通過分析發現用戶只是在通過聊天調整文章內容,而不知道AI還能控制文章的藝術意境,則可以回復用戶你可以嘗試著對我說“調整文章的藝術意境為非現實主義風格”。
PhaseControlAgent則是用來管理用戶的階段,對于ChatGPT而言也可以是一個分類任務,例如階段分為等等。例如AI判斷可以進行文章模板的制作了,前端可以產生幾個模板選擇的按鈕。
使用不同的Agent來處理用戶輸入的不同任務,包括意圖識別、ChatContext分析、AI回復生成和階段控制,從而協同工作,為用戶生成一篇倫敦游記的文章,提供不同方面的幫助和引導,例如調整文章的藝術意境、選擇文章模板等。這樣可以通過多個Agent的協作,使用戶獲得更加個性化和滿意的文章生成體驗。?
Prompt微調
LLM雖然很厲害,但離統治人類的AI還相差甚遠。眼下有個最直觀的痛點就是LLM的模型參數太多,基于LLM的模型微調變得成本巨大。例如GPT-3模型的參數量級達到了175Billion,只有行業大頭才有這種財力可以微調LLM模型,對于小而精的公司而言該怎么辦呢。無需擔心,算法科學家們為我們創新了一個叫做prompttuning的概念。
Prompttuning簡單理解就是針對prompt進行微調操作,區別于傳統的fine-tuning,優勢在于更快捷,prompttuning僅需微調prompt相關的參數從而去逼近fine-tuning的效果。

Figure11.Promptlearning
什么是prompt相關的參數,如圖所示,prompttuning是將prompt從一些的自然語言文本設定成了由數字組成的序列向量。本身AI也會將文本從預訓練模型中提取向量從而進行后續的計算,只是在模型迭代過程中,這些向量并不會跟著迭代,因為這些向量于文本綁定住了。但是后來發現這些向量即便跟著迭代也無妨,雖然對于人類而言這些向量迭代更新后在物理世界已經找不到對應的自然語言文本可以表述出意思。但對于AI來講,文本反而無意義,prompt向量隨著訓練會將prompt變得越來越符合業務場景。
假設一句prompt由20個單詞組成,按照GPT3的設定每個單詞映射的向量維度是12288,20個單詞便是245760,理論上需要訓練的參數只有245760個,相比175billion的量級,245760這個數字可以忽略不計,當然也會增加一些額外的輔助參數,但同樣其數量也可忽略不計。
問題來了,這么少的參數真的能逼近?finetuning的效果嗎,當然還是有一定的局限性。如下圖所示,藍色部分代表初版的prompttuning,可以發現prompttuning僅有在模型參數量級達到一定程度是才有效果。雖然這可以解決大多數的場景,但在某些具體垂直領域的應用場景下則未必有用。因為垂直領域的微調往往不需要綜合的LLM預訓練模型,僅需垂直領域的LLM模型即可,但是相對的,模型參數不會那么大。所以隨著發展,改版后的prompttuning效果可以完全取代fine-tuning。下圖中的黃色部分展示的就是prompttuningv2也就是第二版本的prompttuning的效果。
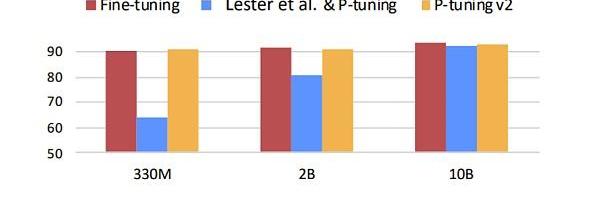
Figure12.Promptlearningparameters
V2的改進是將原本僅在最初層輸入的連續prompt向量,改為在模型傳遞時每一個神經網絡層前均輸入連續prompt向量,如下圖所示。

Figure13.Promptlearningv2
還是以GPT3模型為例,GPT3總從有96層網絡,假設prompt由20個單詞組成,每個單詞映射的向量維度是12288,則所需要訓練的參數量=96*20*12288=23592960。是175billion的萬分之1.35。這個數字雖不足以忽略不計,但相對而言也非常小。
未來可能會有prompttuningv3,v4等問世,甚至我們可以自己加一些創新改進prompttuning,例如加入長短期記憶網絡的設定。(因為原版的prompttuningv2就像是一個大型的RNN,我們可以像改進RNN一般去改進prompttuningv2)。總之就目前而言,prompttuning使得微調LLM變得可行,未來一定會有很多垂直領域的優秀模型誕生。
總結
LargeLanguageModels(LLMs)和Web3技術的整合為去中心化金融領域帶來了巨大的創新和發展機遇。通過利用LLMs的能力,應用程序可以對大量不同數據源進行全面分析,生成實時的投資機會警報,并根據用戶輸入和先前的交互提供定制建議。LLMs與區塊鏈技術的結合還使得智能合約的創建成為可能,這些合約可以自主地執行交易并理解自然語言輸入,從而促進無縫和高效的用戶體驗。
這種先進技術的融合有能力徹底改變DeFi領域,并開辟出一條為投資者、交易者和參與去中心化生態系統的個體提供新型解決方案的道路。隨著Web3技術的日益普及,LLMs創造復雜且可靠解決方案的潛力也在擴大,這些解決方案提高了去中心化應用程序的功能和可用性。總之,LLMs與Web3技術的整合為DeFi領域提供了強大的工具集,提供了有深度的分析、個性化的建議和自動化的交易執行,為該領域的創新和改革提供了廣泛的可能性。
參考文獻

頭條 ▌BRC-20代幣總市值接近4億美元數據顯示,比特幣銘文代幣Ordi現報12.48美元,24小時漲幅30.54%,當前總市值已達2.62億美元.
1900/1/1 0:00:00文章來源:新智元 編輯:Aeneas好困 最新研究結果表明,AI在心智理論測試中的表現已經優于真人。GPT-4在推理基準測試中準確率可高達100%,而人類僅為87%.
1900/1/1 0:00:00隨著投資者擔憂美國銀行業危機進一步深化,比特幣引領加密市場強勢反彈。比推終端數據顯示,比特幣打破了連續五天的下跌趨勢,突破2.9萬美元,盤中一度觸及3萬美元,市值第二大加密貨幣以太坊上漲4.5%.
1900/1/1 0:00:00撰文:SuiNetwork本文將為開發人員在SuiNetwork上的最佳實踐做快速參考。Sui是基于第一原理重新設計和構建而成的L1公有鏈,旨在為創作者和開發者提供能夠承載Web3中下一個十億用.
1900/1/1 0:00:005月6日下午,科大訊飛召開了名為“訊飛星火認知大模型”的成果發布會,同步發布了訊飛AI學習機、訊飛聽見、訊飛智能辦公本、訊飛智能座艙和訊飛開放平臺等5項應用成果.
1900/1/1 0:00:00關鍵要點 盡管智能合約?Layer??1?不斷成為頭條新聞,但比特幣仍然保留了它在加密貨幣市值排行榜上的主導地位。盡管如此,比特幣的可持續性值得討論.
1900/1/1 0:00:00


