






 BTC/HKD-1.82%
BTC/HKD-1.82% ETH/HKD-3.77%
ETH/HKD-3.77% LTC/HKD-2.53%
LTC/HKD-2.53% DOT/HKD-5.02%
DOT/HKD-5.02% ADA/HKD-5.09%
ADA/HKD-5.09% SOL/HKD-1.27%
SOL/HKD-1.27% XRP/HKD-4.58%
XRP/HKD-4.58% DOGE/US-5.13%
DOGE/US-5.13%來源:新智元編輯:Aeneas好困
快速定制模型的LLM引擎Lamini來了,開發者狂喜!
ChatGPT雖好,但始終有門檻。通常,只有擁有AI博士學位的大型機器學習團隊,才能這樣訓練一個模型。
為了把這個門檻打下來,團隊構建了Lamini引擎,從此,每個開發者都能夠擁有從GPT-3訓練ChatGPT的超能力!
劃重點:可以商用!可以商用!可以商用!
項目地址:https://github.com/lamini-ai/lamini/
Lamini的開發團隊表示,你需要的只是幾行代碼,就可以用托管數據生成器倆訓練自己的LLM,包括權重和其他所有的內容。
此外,你也可以使用開源的LLM,用Lamini庫對生成的數據進行微調。以及訪問完整的LLM訓練模塊,使用從LoRa等速度優化,到虛擬私有云(VPC)部署等企業功能。

對此,英偉達科學家JimFan表示,LLaMa+自定義數據正在成為新的范式,而Lamini的推出也帶了一種全新的模式——FaaS,微調即服務。

知情人士:澳大利亞官員要求幣安員工提供其個人設備上的內部通信和數據副本:金色財經報道,據知情人士透露,澳大利亞官員本周直接找到了幣安在當地運營機構的現任和前任員工,要求提供其個人設備上的內部通信和數據副本。澳大利亞證券和投資委員會(ASIC)本周在該公司辦公室外單獨聯系了幣安的代表,Binance目前在世界許多地方都面臨著法律方面的阻力,而其首席執行官否認法律和合規管理人員的連續離職是令人擔憂的原因。[2023/7/8 22:25:23]
MLOps的未來是「LMOps」。哪里有標準化,哪里就有機會。
OpenAI科學家,前特斯拉人工智能總監AndrejKarpathy也表示,LLM定制化的生態正在愈發火爆。
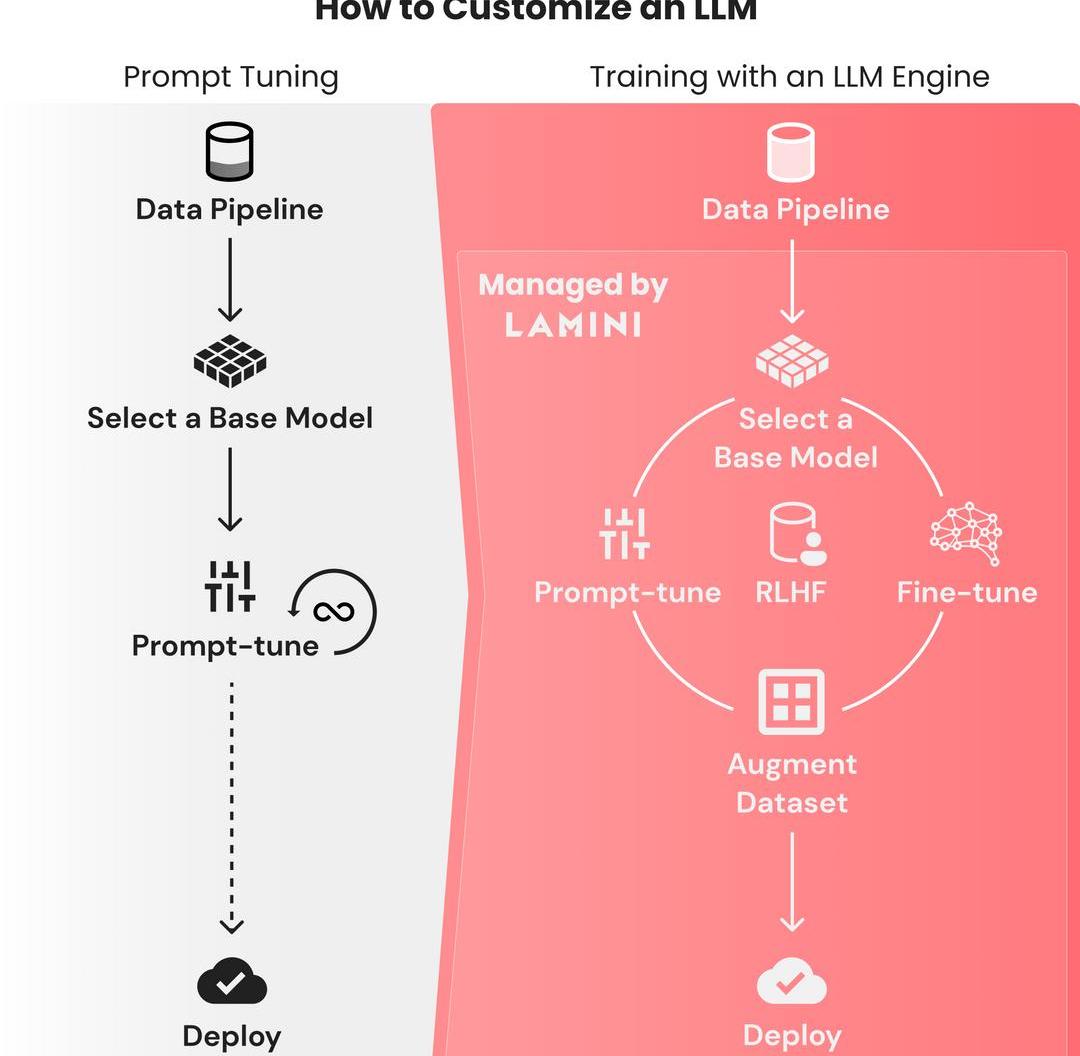
訓LLM就像prompt-tuning一樣簡單
寫一個prompt如此容易,但想要從基礎模型訓練出一個大語言模型,卻是如此困難。
因為需要花費大量時間,來找出微調模型失敗的原因,所以對數據集微調的迭代周期都是以月為單位的。
與之相反,微調prompt的迭代,只需要幾秒鐘,并且在幾個小時內,性能都能保持穩定。
這個過程只需要把有限數量的數據整合到prompt中就可以了,并不需要動輒幾TB的數據。
ChatGPT的誕生十分艱難,OpenAI的團隊花了幾個月的時間,在基礎的GPT-3模型上微調,并進行RLHF。這個門檻極高,只有大型的ML團隊才能完成這種訓練。
Binance.US上的比特幣價格在今日上午短暫“閃漲”至超過13.8萬美元:金色財經報道,據Binance.US官網數據顯示,北京時間6月21日上午,Binance.US上的USDT市場的比特幣價格短暫“閃漲”超過138,000美元,最高達到了138,070美元,比其他交易所顯示的現貨比特幣價格高出近400%。數據顯示,價格突然的短暫“閃漲”只持續了幾秒鐘。[2023/6/21 21:52:11]
有500強企業的技術負責人這樣抱怨過:「我們團隊的10名機器學習工程師用了OpenAI的微調API,結果我們的模型反而變得更差了,怎么辦啊。」
「我真的不知道該怎么充分利用數據,我已經用盡了所有從在線教程中能學到的prompt魔法了。」
這,就是研究者構建Lamini的原因:讓每個開發者可以直接從GPT-3訓練ChatGPT。
任意LLM,秒變ChatGPT!
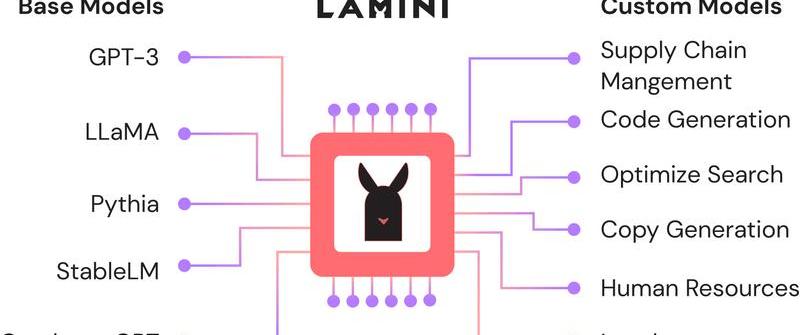
Lamini是一個LLM引擎,可以讓不僅僅是機器學習專家的任何開發人員,都能在大型數據集中,把高性能的LLM訓練得像ChatGPT一樣好。
這個過程,只需要Laimini庫的幾行代碼即可。
值得注意的是,這個庫中的優化遠遠超出了現在開發者可以使用的范圍,從更具挑戰性的優化到更簡單的優化。
比如,你想從不同的角度生成一個廣告文案。
首先,從llama模塊導入LLM引擎:
fromllamaimportLLMllm=LLM(name="marketing")
接下來,需要定義輸入和輸出類型。注意,這里一定要包括上下文,因為可以有助于LLM在自然語言中進行理解。
Gala Games推出100萬美元的漏洞賞金計劃:5月24日消息,區塊鏈游戲平臺 Gala Games 宣布與 Web3 漏洞賞金平臺 Immunefi 合作推出總獎金為 100 萬美元的漏洞賞金計劃,旨在消除其錯誤和增強安全性。[2023/5/24 15:23:07]
fromllamaimportType,ContextclassAdAspects(Type):tone:str=Context("toneofthemarketingcopy")product_features:list=Context("productfeaturestopromote")audience:str=Context("targetaudienceforthemessage")subject:str=Context("subjectortopicofthemessage")goal:str=Context("goalofthismarketingcampaignandmessage")classAdCopy(Type):title:str=Context("googleadtitletag")description:str=Context("googleaddescription")keywords:list=Context("keywordsforthesearchengine")
然后就可以開始提問了:
語氣:大膽,但不傲慢
特色:亞洲醬料和香料、家常調料和套餐包,可以輕松在家烹飪。
aspects=AdAspects(tone="boldandbright,butnotarrogant",product_features=,audience="suburbanfamilies",subject="deliciousasianmealswithoutgoingtoarestaurant",goal="getsuburbanmomsanddadstotrybuytheirfirstomsompackorfreetastingkit")ad_copy=llm(input=aspects,output_type=AdCopy)print(f"Adcopy:{ad_copy}")模型輸出:
人民銀行:進一步提高數字人民幣研發試點攻堅能力:金色財經報道,2023年4月4日,人民銀行召開2023年貨幣金銀和安全保衛工作電視會議。會議強調,貨幣發行和現金服務事關人民群眾切身利益。當前,現金運行態勢深刻變化,高質量發展要求建立更科學、更具彈性的現金供應體系,構建更均等、更普惠、更能滿足群眾現金使用需求的服務新格局,形成更高治理水平、更加市場化、更好激發新動能的貨金保衛管理新模式,同時要進一步提高數字人民幣研發試點攻堅能力,更好統籌發展與安全。[2023/4/6 13:48:28]
嘗試Omsom的美味亞洲醬料、香料、家常調料和套餐包。輕松為家人在家做出美味佳肴。
>title='DeliciousAsianMealsWithoutGoingtoaRestaurant|Omsom'description="TryOmsom'sdeliciousAsiansauces,aromatics,andhome-cookedseasoningsandmealpacks.Easilycookdeliciousmealsathomeforyourfamily."keywords=
如何創建自己的「ChatGPT」
基礎模型能理解一般的英語,但如果需要它們學習一些垂直語言和規則,prompt微調并不足夠,很多時候我們都需要構建自己的LLM。
利用用下面這個步驟,就能獲得像ChatGPT一樣遵循指令的LLM。

嘗試prompt-tuningChatGPT或其他模型
數據:165000000枚XRP從FTX轉入未知錢包:金色財經報道,WhaleAlert數據顯示,165,000,000枚XRP(約58,985,368美元)從FTX轉移至未知錢包。[2022/9/13 13:25:21]
可以使用Lamini庫的API,在不同模型之間快速進行prompt-tuning,只需一行代碼,即可在OpenAI和開源模型之間切換。
Lamini庫已經優化了正確的prompt,這樣開發者就可以使用不同的模型,不必擔心如何為每個模型設置prompt的格式。
構建一個包含輸入-輸出對的大型數據集
這些數據集會向模型展示,它應該如何響應輸入,無論是遵循英文說明,還是以JSON響應。
研究者剛剛發布了一個只有幾行代碼的repo,使用Lamini庫,僅從100個數據點中,就能生成50k數據點。
而且因為使用Lamini庫來啟動Lamini引擎,所以這個過程根本不需要用到GPU。
在repo中,已經包含一個開源的70+k數據集。

項目地址:https://github.com/lamini-ai/lamini/
在大型數據集上微調基礎模型
除了數據生成器,研究者還發布了一個LLM,它使用Lamini對生成的數據進行了微調。以編程方式執行此操作的功能也會很快發布。
也可以把OpenAI的微調API作為起步。
在微調模型上進行RLHF
使用Lamini,就不再需要大型ML和人工標記團隊來運行RLHF。
部署到云端
只需點擊產品或功能中的API端點即可。
專為LLM打造的數據生成器
簡單來說,依照以下幾個步驟,就可以訓練自己的大語言模型了。
用于優化prompt微調和類型化輸出的Lamini庫。
用于微調和RLHF的高級Lamini庫,只需幾行代碼。
史上首個托管數據生成器,用于創建數據,來訓練遵循指令的LLM。注意,已獲得商業使用許可!
開源的指令跟隨LLM,使用上述工具,只需幾行代碼即可完成。
數據生成器工作原理
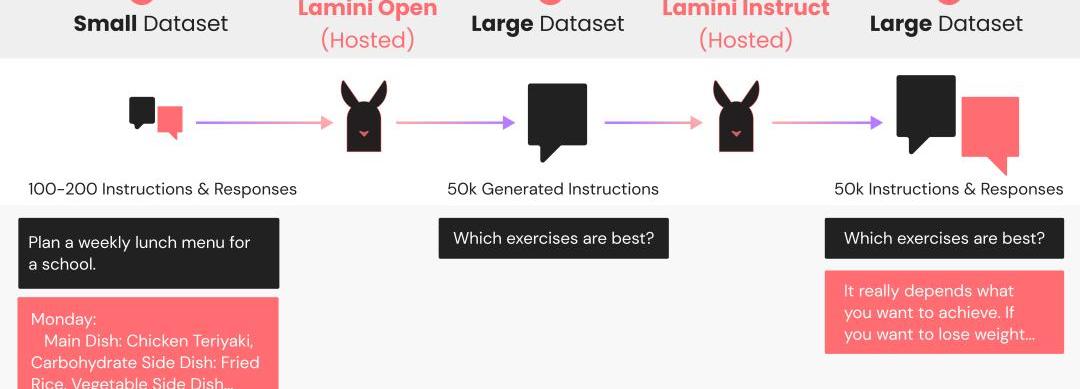
Lamini數據生成器是一個LLM管線,它采用原始的100多條指令的小集合,與預期的響應配對,生成50k+新的配對,靈感來自Stanford的Alpaca。這個生成管線使用Lamini庫來定義和調用LLM,以生成不同但相似的指令和響應對。
根據這些數據訓練后,你的LLM會遵循這些指示,因而得到改進。對于使用開源LLM的生成管線,研究者提供了一個很好的默認值,LaminiOpen和LaminiInstruct。
隨著每天新的LLM發布,研究者都會將默認值更新為性能最佳的模型。在目前的版本中,LaminiOpen用的是EleutherAI的Pythia,LaminiInstruct用的是Databricks的Dolly。
LaminiOpen會生成更多指令,而LaminiInstruct會生成這些指令的成對響應。
最終生成的數據集可供免費商業使用,已經通過CC-BY許可。
僅用一行代碼,就可以將Lamini庫的默認值換成其他開源或OpenAI模型。
研究者發現,OpenAI模型的平均表現更好,但它們的許可限制了將生成數據用于訓練類ChatGPT模型的商用。
對生成數據進行微調
在這個過程中,生成的數據會質量不一。
在微調之前,下一步就是將生成的數據過濾為高質量數據。
然后,Lamini會通過在這個過濾后生成的數據集上訓練基礎模型,來創建自定義LLM。
研究者已經發布了一個開源指令跟隨LLM,可以用Lamini來訓練Pythia基礎模型,生成的37k指令是從70k中篩選出來的。
顯然,Lamini庫的出現,讓迭代周期變得更快、更有效,有更多的人能夠構建模型,而不僅僅是試驗各種prompt。
團隊介紹
SharonZhou是Lamini的聯合創始人兼首席執行官。

個人主頁:https://sharonzhou.me/
她在哈佛大學獲得了計算機科學與古典文學聯合學士學位,并以最高榮譽獲得了碩士學位。
隨后,她在斯坦福大學獲得了計算機科學博士學位,師從吳恩達。

2022年,29歲的Zhou入選《麻省理工科技評論》「35歲以下科技創新35人」。

GregoryDiamos是MLPerf的聯合創始人。
他曾是百度硅谷AI實驗室的創始成員,對DeepSpeech和DeepVoice系統有貢獻。

參考資料:
https://lamini.ai/blog/introducing-lamini
頭條 Coinbase面向非美國機構用戶推出國際交易所Odaily星球日報訊Coinbase?今日宣布推出?CoinbaseInternationalExchange.
1900/1/1 0:00:00Cetus是一個基于Move生態的Dex和流動性協議,使用類似于uniswapV3的算法構建集中性流動性協議和一系列附屬功能,為DeFi用戶提供最佳的交易體驗和更高的資金效率.
1900/1/1 0:00:005月7日,跨鏈互操作性項目?Interlay的創始人AlexeiZamyatin提議推出BRC-21標準,以向比特幣網絡上引入完全去中心化的跨鏈資產,并在閃電網絡中使用它們.
1900/1/1 0:00:00出品:ThePrimediaDAO作者:Jerry@ThePrimedia,0xLeon我們已經感受到香港Web3的敘事正在OnchainRealWorldAssets.
1900/1/1 0:00:00來源|financemagnates 編譯|潮外音 區塊鏈是顛覆游戲業務的最新突破,這對創新并不陌生。通過為玩家提供游戲所有權、交易和玩游戲的新選擇,區塊鏈有能力徹底改變游戲業務.
1900/1/1 0:00:00來源:量子位 隨便一張照片,就可生成3D頭像。而且光線真實,任意角度可調。這是蘋果的最新黑科技生成框架FaceLit。 正如其名,FaceLit的特色就是可以將人臉“點亮”.
1900/1/1 0:00:00


