






 BTC/HKD+1.04%
BTC/HKD+1.04% ETH/HKD+0.9%
ETH/HKD+0.9% LTC/HKD+0.11%
LTC/HKD+0.11% DOT/HKD+1.36%
DOT/HKD+1.36% ADA/HKD+1.85%
ADA/HKD+1.85% SOL/HKD+4.56%
SOL/HKD+4.56% XRP/HKD+1.22%
XRP/HKD+1.22% DOGE/US+1.14%
DOGE/US+1.14%來源:阿爾法工場
最近,正在進行AI大戰的各個大廠,被谷歌泄漏的一份內部文件,翻開了窘迫的一面。
這份泄露的內部文件聲稱:“我們沒有‘護城河’,OpenAI也沒有。當我們還在爭吵時,第三個方已經悄悄地搶了我們的飯碗——開源。”
這份文件認為,現在的一些開源模型,一直在照搬谷歌、微軟這些大廠的勞動成果,并且雙方差距正在以驚人的速度縮小。開源模型更快、可定制性更強、更私密,而且功能性也不落下風。
比如,這些開源模型可以用100美元外加13B參數,加上幾個禮拜的時間就能出爐,而谷歌這樣的大廠,要想訓練大模型,則需要面對千萬美元的成本和540B參數,以及長達數月的訓練周期。
那么,事實是否真的像這份文件所說的那樣,谷歌和OpenAI在AI方面的種種積累,最終真的會敗給一群隱藏在民間的“草頭俠”?
所謂“大廠壟斷大模型”的時代,真的要終結了嗎?
要回答這個問題,我們就得先了解下目前開源模型的生態,看看這些如雨后春筍般涌現的開源模型,究竟是如何一步步蠶食谷歌這些“正規軍”的江山的。
“大空頭”Michael Burry:我們將看到另一個通貨膨脹高峰:金色財經報道,對沖基金經理、電影《大空頭》原型Michael Burry發布推文表示,美國通貨膨脹達到頂峰,但這不是這個周期的最后一個高峰。他在推文中警告道,我們很可能會看到CPI走低,2023年下半年可能為負值,而且無論從哪個定義來看,美國都將陷入衰退。美聯儲將降息,政府將刺激。我們將有另一個通貨膨脹高峰,這并不難。
美聯儲將于2023年 1 月 4 日發布其聯邦公開市場委員會 (FOMC) 會議紀要,為未來的政策提供指導。[2023/1/3 22:21:13]
01異軍突起的開源模型
其實,最早的開源模型,其誕生完全是一場“偶然”。
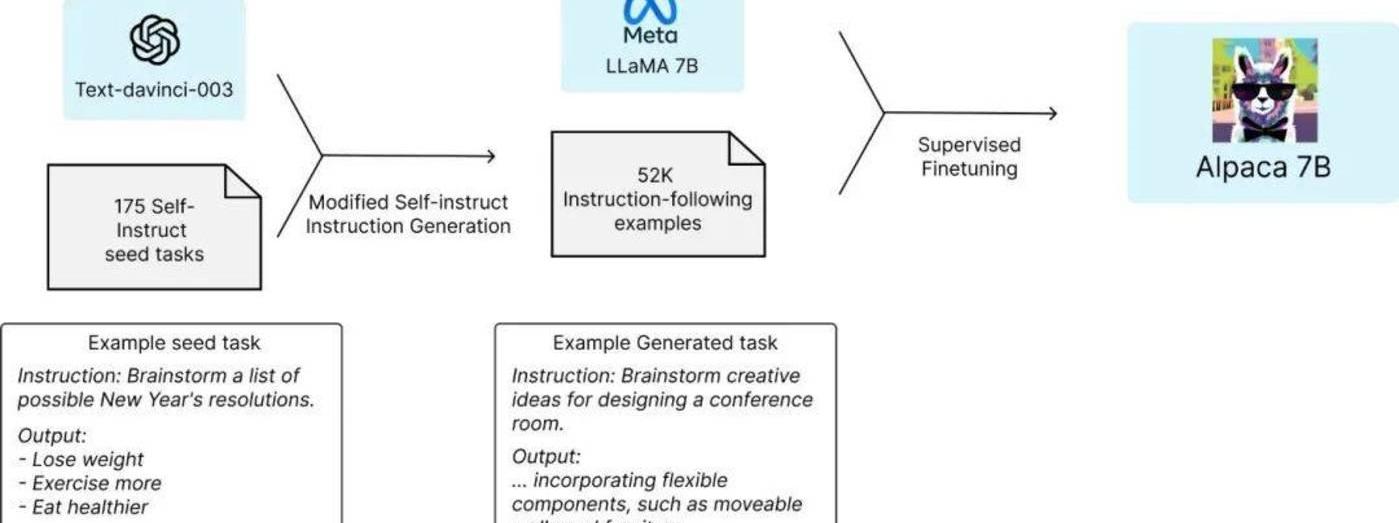
今年2月,Meta發布了自家的大型語言模型LLaMA,參數量從70億到650億不等,并僅用130億的參數,就在大多數基準測試下超越了GPT-3。
但萬萬沒想到的是,剛發布沒幾天,LLaMA的模型文件就被泄露了。
至此之后,開源模型的浪潮就如決堤一般,變得一發不可收拾。
如八仙過海一般的ChatGPT開源替代品——「羊駝家族」,隨即粉墨登場。
風險投資家Tim Draper:去中心化的加密貨幣是經濟發展的“大好機會”:金色財經報道,風險投資家Tim Draper淡化了 FTX 崩潰的重要性,認為失敗的加密交易平臺集中在一個人身上。 Draper 呼應比特幣擁護者的主要論點,強調世界上最大的加密貨幣實際上是去中心化的。?
Tim Draper進一步聲稱,去中心化的加密貨幣是經濟發展的“大好機會”。? 此外,Draper指出,企業必須設計出能夠對在“比特幣錢包花園”中運營的企業征稅的軟件。這樣一來,他們就會更加信任最大的加密貨幣。?[2022/12/4 21:21:37]
與ChatGPT這類大模型相比,此類開源模型最顯著的特點,就是訓練成本與時間都極其低廉。
以LlaMA的衍生模型Alpaca為例,其訓練成本僅用了52k數據和600美元。
然而,如果開源光靠低成本,還不足以讓谷歌這類大廠感到威脅,重要的是,在極低的訓練成本下,這些開源模型還能屢次達到和GPT-3.5匹敵的性能。
這下谷歌和OpenAI就坐不住了。
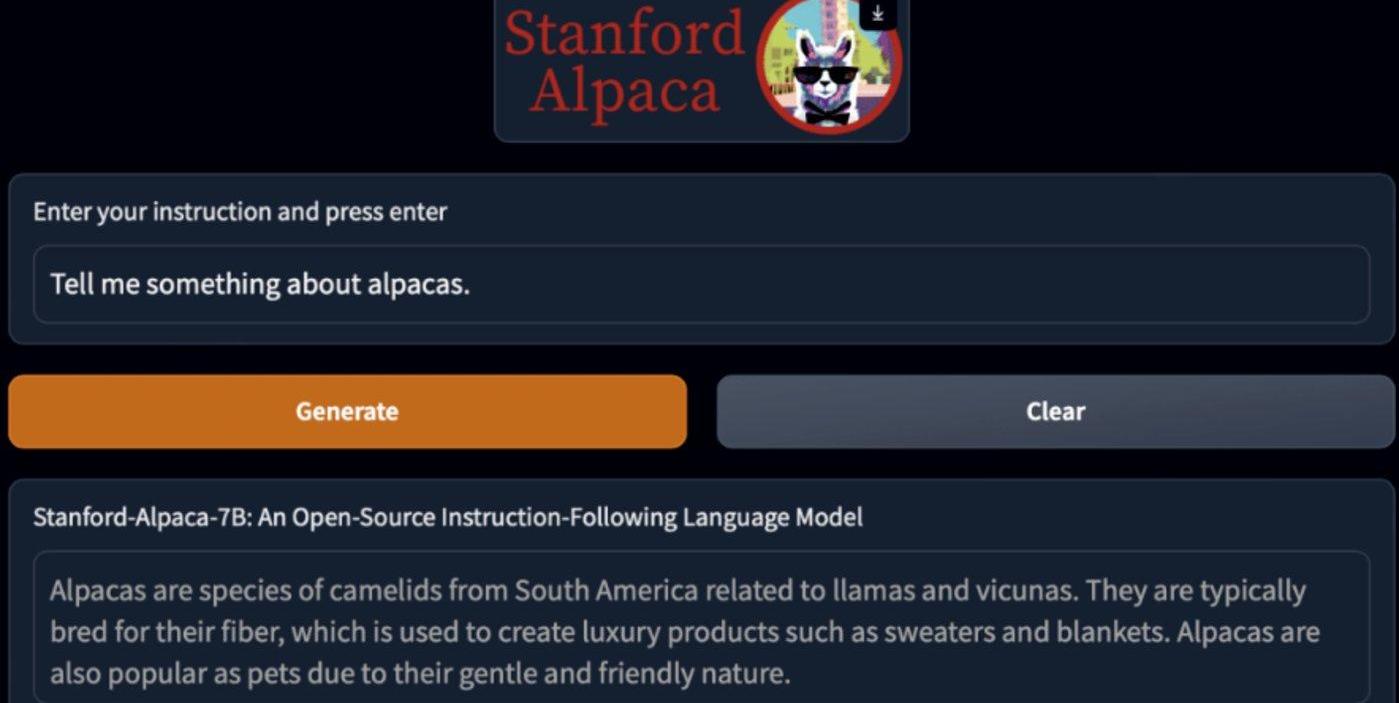
斯坦福研究者對GPT-3.5和Alpaca7B進行了比較,發現這兩個模型的性能非常相似。Alpaca在與GPT-3.5的比較中,獲勝次數為90對89。
聲音 | ETC Cooperative執行董事:以太坊基金會沒有公布“大多數基金會事務”的信息:據AMBcrypto 1月5日消息,ETC Cooperative執行董事Bob Summerwill表示,以太坊基金會一個與加密貨幣有關的不透明的瑞士基金會。基金會有責任和問責制,以顯示自己不邪惡,但值得信賴的成熟治理和運作的透明度,類似于任何其他非營利組織。Summerwill聲稱,世界上沒有任何非營利組織擁有一張免費卡,可以按照自己的意愿行事。Summerwill還表示,以太坊基金會沒有公布“大多數基金會事務”的信息。[2020/1/6]
重點來了:這些開源模型,究竟是怎么做到這點的?
斯坦福團隊的答案是兩點:1、一個強大的預訓練語言模型;2、一個高質量的指令遵循數據。
在這里,我們將強大的預訓練語言模型,比喻為一位有著豐富知識和經驗的老師。
對于自然語言處理領域的任務,強大的預訓練語言模型,可以利用大規模的文本數據進行訓練,學習到自然語言的模式和規律,并且可以幫助指令遵循等任務的模型更好地理解和生成文本,提高模型的表達和理解能力。
這就相當于學生使用老師的知識和經驗,來提高語言能力,指令遵循等任務的模型可以使用預訓練語言模型的知識和經驗來提高自己的表現。
動態 | 以色列稅務局說服當地交易所上報“大額交易者”:據bitcoin.com報道,以色列稅務局已說服當地交易所Bits of Gold報告“大額交易者”,即任何在12個月內交易總額達5萬美元或以上的交易者。據悉此前,在該國經營的交易所已向以色列洗錢和恐怖融資禁令管理局報告了大筆交易,但這些信息并不容易到達稅務機關。此外,以色列稅務局沒有法律權利強迫公司在未經同意的情況下報告其客戶信息。[2018/7/5]
除了借助這位“老師”的知識外,開源模型的另一“利刃”,就是指令微調。
指令微調,或指令調優,是指現有的大語言模型生成指令遵循數據后,對數據進行優化的過程。
具體來說,指令微調是指在生成的指令數據中,對一些不合適或錯誤的指令進行修正,使其更符合實際應用場景。
而指令調優是指在生成的指令數據中,對一些重要、復雜或容易出錯的指令進行加重或重復,以提高指令遵循模型對這些指令的理解和表現能力。
憑借著這樣的“微調”,人們可以生成更準確、更有針對性的指令遵循數據,從而提高開源模型在特定任務上的表現能力。
如此一來,即使只用很少的數據,開源社區也能訓練出性能匹敵ChatGPT的新模型。
然而,又一個問題是:面對自己辛苦打下的江山,被開源社區用“四兩撥千斤”的方式步步蠶食,谷歌和OpenAI為何一直沒有予以反制呢?
比特幣“大咖”泰勒·文克萊沃斯:萊特幣是比特幣的“測試網“:據inverse報道,比特幣“大咖”泰勒·文克萊沃斯稱萊特幣是比特幣的“測試網(testnet)”,他認為萊特幣基本上是用于潛在比特幣功能的測試,而且是嚴格按照替代比特幣區塊鏈測試目的設計的。[2018/3/2]
哪怕是如法炮制,以攻,推出同樣快速迭代的小模型,也不失為一種破局之策啊。
02騎虎難下
實際上,谷歌這樣的頭部企業,不是沒有意識到開源的優勢。
在那份泄漏的文件中,谷歌就提到:幾乎任何人都能按照自己的想法實現模型微調,到時候一天之內的訓練周期將成為常態。以這樣的速度,微調的累積效應將很快幫助小模型克服體量上的劣勢。
可問題是,身為AI領域巨頭的谷歌和OpenAI,既不能,也不愿完全放棄訓練成本高昂的大參數模型。
從某種程度上說,這是其保證自身優勢地位的必要手段。
作為AI領域的巨頭,谷歌和OpenAI需要不斷提升自己的技術實力和創新能力。而傳統的大參數訓練模型,則是提供這一探索和創新的必經之路。
因為大模型的底層技術若想取得突破,AI領域的研究者和科學家,就需要更深入地理解模型和算法的基本原理,探索AI技術的局限性和發展方向,這需要進行大量的理論研究、實驗驗證和數據探索,而不僅僅是微調和優化。
例如,在訓練大參數模型時,AI領域的科學家,可以探索模型的泛化能力和魯棒性,在不同的數據集和場景下評估模型的性能和效果。谷歌的BERT模型,也正是在此過程中得到了不斷強化。
同時,大參數模型的訓練,還可以幫助科學家探索模型的可解釋性和可視化,
例如,對今天的GPT來說至關重要的Transformer模型,雖然在性能上表現出色,但其內部結構和工作原理卻相對復雜,不利于理解和解釋。
通過大參數模型的訓練,人們可以可視化Transformer模型的內部結構和特征,從而更好地理解模型是如何對輸入進行編碼和處理的,并進一步提高模型的性能和應用效果。
因此,開源和微調的方式,雖然可以促進AI技術的快速發展和優化,但不足以替代對AI基礎問題的深入研究和探索。
但話說到這,一個十分尖銳的矛盾又擺了出來:一方面,谷歌和OpenAI不能放棄對大參數模型的研究,并堅持對其技術進行保密。但另一方面,免費、高質量的開源替代品,又讓谷歌等大廠的“燒錢”策略難以為繼。
因大模型耗費的巨大算力資源和數據,僅是在2022年,OpenAI總計花費就達到了5.4億美元,與之形成鮮明對比的,則是其產生的收入只有2800萬美元。
與此同時,開源社區的具有的靈活性上的優勢,也讓谷歌等大廠感到難以匹敵。
在那份泄漏的文件中,谷歌就認為:開源陣營真正的優勢在于“個人行為”。
相較于谷歌這些大廠,開源社區的參與者可以自由地探索和研究技術,不受任何限制和壓力,從而有更多機會發現新的技術方向和應用場景。
而谷歌研究和開發新技術時,則必須考慮產品的商業可行性和市場競爭力。這就對人才的研究方向產生了一定的限制和約束。
此外,由于保密協議的存在,谷歌的人才也難以像開源社區那樣,與外界充分地交流和分享技術研究的成果。
如果說,低價、靈活的開源模型,終將成為一種不可阻擋的趨勢,那么當谷歌等大廠面對這浩瀚的戰場時,又該怎樣在新時代生存下去呢?
03另辟蹊徑
倘若谷歌這樣的頭部企業,最終在開源陣營的攻勢下,選擇了“打不過就加入”的策略,那如何在開源的情況下,找到一條可行的商業路徑,就成了一件頭等大事。
畢竟,在目前的市場認知下,開源幾乎就等于“人人皆可免費使用。”
之前,StableDiffusion背后的明星公司——StabilityAI,就因為在開源后,沒有找到明確的盈利途徑,目前正面臨嚴重的財政危機,以至于到了快倒閉的地步。
不過,關于如何在開源的情況下實現盈利,業界也不是完全沒有先例可循。
例如,之前谷歌對Android系統的開源,就是一個經典的案例。
當年,由谷歌主導開發和推廣的Android系統開源后,谷歌仍然通過各種途徑,從Android操作系統的設備制造商那里獲取了收益。
具體來說,這些途徑可分為以下幾種:
1.收取授權費用:當設備制造商希望在其設備上預裝GooglePlay商店等谷歌應用和服務時,他們需要遵守谷歌的授權協議,并支付相應的授權費用。
2.推出定制設備:谷歌通過與設備制造商合作,推出一些定制的Android設備,如GooglePixel智能手機和GoogleNexus平板電腦等,并從中獲得收入。這些定制設備通常具有更高的價值和更好的性能,而且會預裝谷歌的應用和服務。
3.銷售應用:當設備使用者在GooglePlay商店中購買應用、游戲或媒體內容時,谷歌會從中提取一定的傭金。
雖然這些途徑的收益,也許并不像谷歌的主業——搜索和廣告那樣讓其賺得盆滿缽滿,但谷歌仍然從中獲得了各種“隱性收益”。
因為Android的存在,避免了某一家企業壟斷移動平臺的入口,只要互聯網是開放的,谷歌就能通過吸引更多人使用Android上的應用,來收集用戶的行為數據,對這些數據進行加工,從而使得廣告投放可以更加精準。
由此可見,開源模式并非與商業化的盈利模式完全沖突,這對于谷歌和開源社區的參與者而言,都是一種好事。
因為只有通過商業化途徑,源源不斷地為自身“造血”,谷歌和OpenAI等大廠,才能繼續承擔起訓練大參數模型所需的巨額成本。
而只有大參數模型的持續研發,各大開源社區,才能繼續以高性能、高質量的預訓練語言模型為基礎,微調出種類更多,應用場景更為豐富的開源模型。
基于這樣的關系,開源模型與封閉的大模型之間,其實不僅僅只是對立與競爭,同時也是一種互助共生的生態。
Tags:PENOPENNAI比特幣openaurumOpenpayMonopoly Millionaire Game量子比特幣包括
各位朋友,歡迎來到SignalPlus宏觀點評。SignalPlus宏觀點評每天為各位更新宏觀市場信息,并分享我們對宏觀趨勢的觀察和看法。歡迎追蹤訂閱,與我們一起關注最新的市場動態.
1900/1/1 0:00:002023年4月,溫州多家科研機構、科技公司和社會組織共同發起了溫州AIGC產業聯盟,并與溫州市服裝商會共同發起“首屆溫州鞋服產業AIGC設計大賽”活動.
1900/1/1 0:00:00七位院士領銜開講,頂尖科學家激蕩的頭腦風暴;丁磊樊綱馮侖同臺,洞察由科技改變的未來。12月18日-20日,2020年網易未來大會將在杭州“小蓮花”中心盛大舉行.
1900/1/1 0:00:00原文作者:Tide 原文編譯:Felix,PANews跨鏈橋是Web3中競爭最激烈的賽道之一,跨鏈橋希望吸引新用戶并將其轉化為老用戶.
1900/1/1 0:00:00作者:RISCZero高級工程師ErikKaneda;編譯:Maxlion 前言 本文將對比zkEVM和zkVM在技術上的差異,并介紹RISCZerozkVM及其即將推出的Bonsai網絡.
1900/1/1 0:00:00由于BTC網絡并不支持圖靈完備的智能合約,因此自BTC誕生起,長期以來被用于點對點轉賬及價值儲存外的其他場景并不太多.
1900/1/1 0:00:00


