






 BTC/HKD-0.61%
BTC/HKD-0.61% ETH/HKD-2.28%
ETH/HKD-2.28% LTC/HKD-2.66%
LTC/HKD-2.66% DOT/HKD-1.67%
DOT/HKD-1.67% ADA/HKD-1.09%
ADA/HKD-1.09% SOL/HKD-2.12%
SOL/HKD-2.12% XRP/HKD-2.94%
XRP/HKD-2.94% DOGE/US-2.64%
DOGE/US-2.64%編輯:LRS
注意力機制這么好用,怎么不把它塞到卷積網絡里?最近MetaAI的研究人員提出了一個基于注意力的池化層,僅僅把平均池化層替換掉,就能獲得+0.3%的性能提升!
VisualTransformer作為計算機視覺領域的新興霸主,已經在各個研究任務中逐漸替換掉了卷積神經網絡CNN。
ViT與CNN之間存在著許多不同點,例如ViT的輸入是imagepatch,而非像素;分類任務中,ViT是通過對類標記進行決策等等。
classtoken實際上是ViT論文原作者提出,用于整合模型輸入信息的token。classtoken與每個patch進行信息交互后,模型就能了解到具體的分類信息。
并且在自注意力機制中,最后一層中的softmax可以作為注意力圖,根據classtoken和不同patch之間的交互程度,就能夠了解哪些patch對最終分類結果有影響及具體程度,也增加了模型可解釋性。
但這種可解釋性目前仍然是很弱的,因為patch和最后一層的softmax之間還隔著很多層和很多個header,信息之間的不斷融合后,很難搞清楚最后一層softmax是否真的可以解釋分類。
MakerDAO已通過并執行提高DAI儲蓄率、提高Spark Protocol債務上限等的執行提案:8月7日消息,據MakerDAO治理頁面顯示,北京時間8月5日,MakerDAO社區投票通過增強DSA激活、SparkProtocol債務上限提高、RWA金庫更新、2023年第二季度AVC會員補償、Monetails Clydesdale的DAO決議、啟動項目資金、Spark Proxy Spell執行的執行提案。該提案已于北京時間8月7日執行。
除了將DAI存款利率上調至8%外,其他協議主要變化包括:Spark Protocol直接存款模塊最大債務上限從2000萬枚DAI增加至2億枚DAI;RWA004-A債務上限從700萬枚DAI降至0DAI、RWA002-A協議實施更新;134.1枚MKR分配給AVC會員;Spark Protocol更新DAI利率策略,并將DAI市場貸款價值比(LTV)從74%降至0.01%,DAI清算門檻從76%降至0.01%,WETH市場準備金率從15%降至5%,WETH的variableRateSlope1從3.8%降至3%。[2023/8/7 21:28:45]
所以如果ViT和CNN一樣有視覺屬性就好了!
MakerDAO聯創:Curve漏洞可能是牛市前的最后一次崩盤:金色財經報道,MakerDAO聯合創始人Rune Christensen發布推文稱,周末Curve Finance的漏洞引發了整個去中心化金融領域的廣泛擔憂,這可能對行業有好處。他寫道:“這似乎是一個感嘆‘結束了’的時刻,但也許只是這個周期的黑色星期四,即牛市前的最后一次崩盤,一切都會以一百倍強勁的方式回歸”。
金色財經曾報道,由于使用Vyper編碼語言版本的智能合約中的錯誤,DeFi協議Curve Finance的多個流動性池被利用。由于重入漏洞,攻擊者使用Vyper合約耗盡了多個穩定幣池,2400萬美元的資金被提取。[2023/8/1 16:10:26]
最近MetaAI就提出了一個新模型,用attentionmap來增強卷積神經網絡,說簡單點,其實就是用了一個基于注意力的層來取代常用的平均池化層。

韓國虛擬資產聯合調查組將于今日下午2點20分召開揭牌儀式:金色財經報道,韓國首爾南部地方檢察廳將于今日啟動專門打擊虛擬資產(加密貨幣)犯罪的虛擬資產聯合調查組。這是檢察機關首次設立專門針對加密貨幣的組織。當日下午2時20分,檢方將在南地檢署舉行“虛擬資產犯罪聯合調查組就任儀式”。此外,還將舉行招牌揭牌儀式。現任首爾中央地方檢察廳第三部檢察長李正烈擔任聯合調查組第一任組長,該聯合調查組將從今天開始正式活動。
隨著合資企業的成立,預計檢方將加快對加密貨幣犯罪的調查。目前,南部地方檢察廳正在調查獨立議員金南國涉嫌持有大量加密貨幣、“WEMIX”發行方Wemade的發行欺詐、Haru Invest的存取款暫停、加密貨幣交易所Coinone上市中的腐敗行為等。對于近期被查封搜查的Haru Invest、Delio等虛擬資產客戶的暫停提現事件,聯合調查的可能性很大。金南國議員的代幣嫌疑也有可能在聯合單位進行。[2023/7/26 15:59:03]
仔細一想,池化層和attention好像確實很配啊,都是對輸入信息的加權平均進行整合。加入了注意力機制以后的池化層,可以明確地顯示出不同patch所占的權重。
巨鯨地址在沉寂215天后將其全部穩定幣兌換為3596枚stETH:6月21日消息,據Spot On Chain監測,0xcb1開頭巨鯨地址在沉寂215天后今日將其地址內全部穩定幣(價值約652萬美元的USDT和USDC)兌換為3596枚stETH。[2023/6/21 21:52:10]
并且與經典ViT相比,每個patch都會獲得一個單一的權重,無需考慮多層和多頭的影響,這樣就可以用一個簡單的方法達到對注意力可視化的目的了。

在分類任務中更神奇,如果對每個類別使用不同顏色進行單獨標記的話,就會發現分類任務也能識別出圖片中的不同物體。

基于Attention的池化層
文章中新提出的模型叫做PatchConvNet,核心組件就是可學習的、基于attention的池化層。
推特用戶CryptoNovo被盜三個CryptoPunks,或為釣魚攻擊所致:1月4日消息,推特用戶CryptoNovo發推稱,自己所持有的三個CryptoPunks(#3706、#4608、#965)被盜。慢霧創始人余弦分析稱,三個失竊NFT分別流向了兩個不同的釣魚攻擊地址,被盜應是釣魚所致。[2023/1/4 9:52:34]

模型架構的主干是一個卷積網絡,相當于是一個輕量級的預處理操作,它的作用就是把圖像像素進行分割,并映射為一組向量,和ViT中patchextraction操作對應。
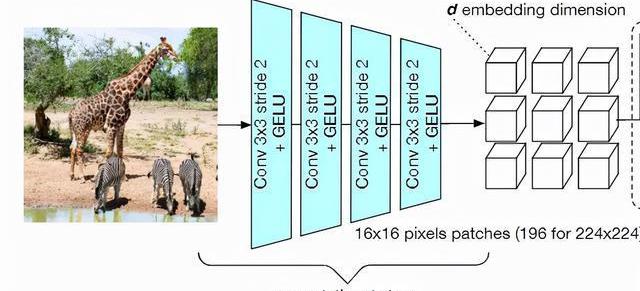
最近也有研究表明,采用卷積的預處理能讓模型的性能更加穩定。
模型的第二部分column,包含了整個模型中的大部分層、參數和計算量,它由N個堆疊的殘差卷積塊組成。每個塊由一個歸一化、1*1卷積,3*3卷積用來做空間處理,一個squeeze-and-excitation層用于混合通道特征,最后在殘差連接前加入一個1*1的卷積。
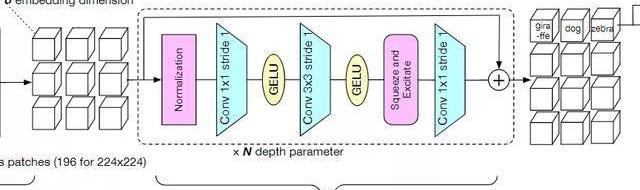
研究人員對模型塊的選擇也提出了一些建議,例如在batchsize夠大的情況下,BatchNorm往往效果比LayerNorm更好。但訓練大模型或者高分辨率的圖像輸入時,由于batchsize更小,所以BatchNorm在這種情況下就不太實用了。
下一個模塊就是基于注意力的池化層了。
在主干模型的輸出端,預處理后的向量通過類似Transformer的交叉注意力層的方式進行融合。
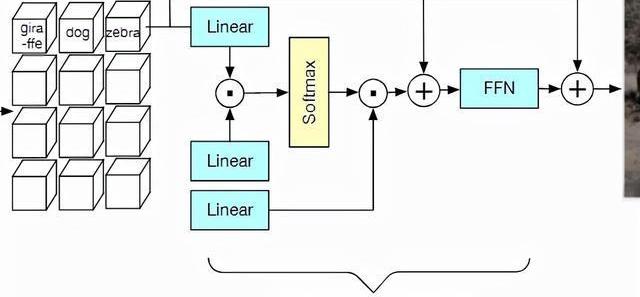
注意力層中的每個權重值取決于預測patch與可訓練向量之間的相似度,結果和經典ViT中的classtoken類似。
然后將產生的d維向量添加到CLS向量中,并經過一個前饋網絡處理。
與之前提出的class-attentiondecoder不同之處在于,研究人員僅僅只用一個block和一個head,大幅度簡化了計算量,也能夠避免多個block和head之間互相影響,從而導致注意力權重失真。
因此,classtoken和預處理patch之間的通信只發生在一個softmax中,直接反映了池化操作者如何對每個patch進行加權。
也可以通過將CLS向量替換為k×d矩陣來對每個類別的attentionmap進行歸一化處理,這樣就可以看出每個塊和每個類別之間的關聯程度。
但這種設計也會增加內存的峰值使用量,并且會使網絡的優化更加復雜。通常只在微調優化的階段以一個小的學習率和小batchsize來規避這類問題。
實驗結果
在圖像分類任務上,研究人員首先將模型與ImageNet1k和ImageNet-v2上的其他模型從參數量,FLOPS,峰值內存用量和256張圖像batchsize下的模型推理吞吐量上進行對比。
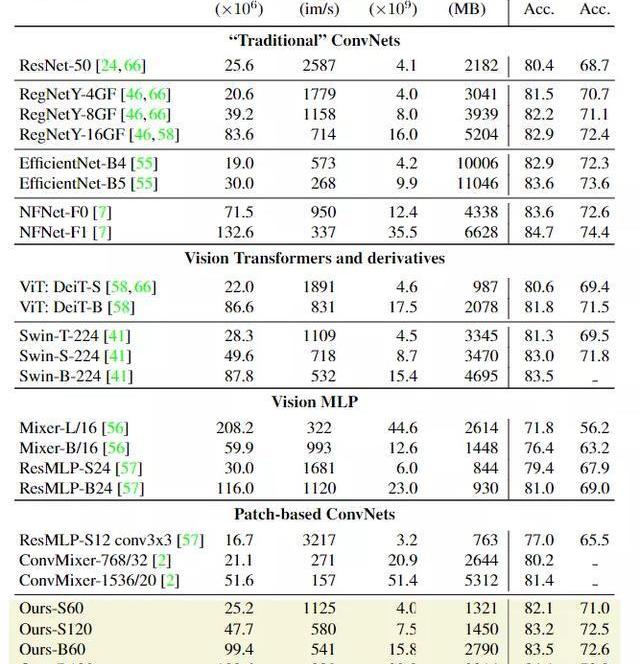
實驗結果肯定是好的,可以看到PatchConvNet的簡單柱狀結構相比其他模型更加簡便和易于擴展。對于高分辨率圖像來說,不同模型可能會針對FLOPs和準確率進行不同的平衡,更大的模型肯定會取得更高的準確率,相應的吞吐量就會低一些。
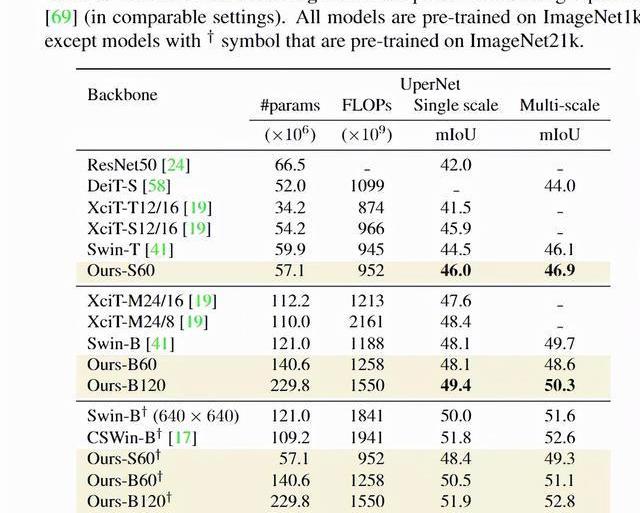
在語義分割任務上,研究人員通過ADE20k數據集上的語義分割實驗來評估模型,數據集中包括2萬張訓練圖像和5千張驗證圖像,標簽超過150個類別。由于PatchConvNet模型不是金字塔式的,所以模型只是用模型的最后一層輸出和UpperNet的多層次網絡輸出,能夠簡化模型參數。研究結果顯示,雖然PatchConvNet的結構更簡單,但與最先進的Swin架構性能仍處于同一水平,并且在FLOPs-MIoU權衡方面優于XCiT。
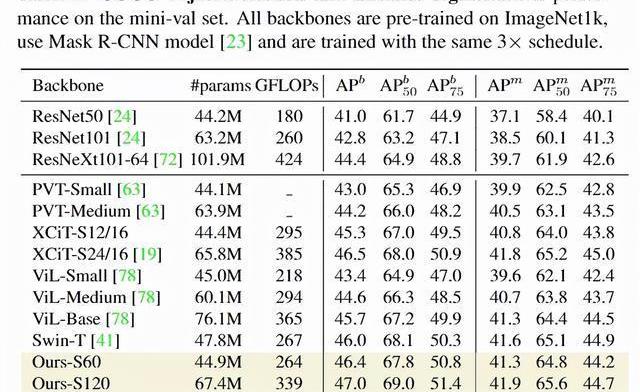
在檢測和實例分割上,研究人員在COCO數據集上對模型進行評估,實驗結果顯示PatchConvNet相比其他sota架構來說,能夠在FLOPs和AP之間進行很好的權衡。
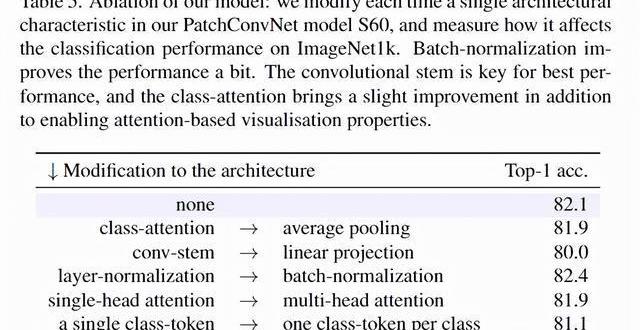
在消融實驗中,為了驗證架構問題,研究人員使用不同的架構對比了Transformer中的classattention和卷積神經網絡的平均池化操作,還對比了卷積主干和線性投影之間的性能差別等等。實驗結果可以看到卷積主干是模型取得最佳性能的關鍵,class-attention幾乎沒有帶來額外的性能提升。
另一個重要的消融實驗時attention-basedpooling和ConvNets之間的對比,研究人員驚奇地發現可學習的聚合函數甚至可以提高一個ResNet魔改后模型的性能。
通過把attention添加到ResNet50中,直接在Imagenet1k上獲得了80.1%的最高準確率,比使用平均池化層的baseline模型提高了+0.3%的性能,并且attention-based只稍微增加了模型的FLOPs數量,從4.1B提升到4.6B。
參考資料:
https://arxiv.org/abs/2112.13692
1元宇宙是什么?一千個哈姆雷特元宇宙起源:超越虛擬與現實的科幻暢想“Metaverse”一詞由前綴“meta”和詞根“verse”組成.
1900/1/1 0:00:00主流日照訊1月28日上午,市海洋發展局與全市農村商業銀行簽訂戰略合作協議。雙方將認真落實省委、省政府海洋強省建設和市委、市政府加快發展向海經濟決策部署,堅持“資源共享、優勢互補、平等互利、合作共.
1900/1/1 0:00:00文丨學術頭條,作者丨BobbyElliott,編譯丨XT自2021年下半年起,“元宇宙”的概念持續升溫。當大眾還在理解這個新概念時,一些國內外科技巨頭已在元宇宙領域展開布局.
1900/1/1 0:00:00湖南日報新湖南客戶端訊記者近日獲悉,上海星圖比特信息技術服務有限公司最近完成了千萬級人民幣融資.
1900/1/1 0:00:00來源:中國新聞網 科研人員在實驗室進行研究。雷鍵攝 中新網重慶11月24日電11月23日,重慶高新區國家生物產業基地的重慶高晉生物科技有限公司宣布,基于非放射性同位素硼-10,成功開發出首.
1900/1/1 0:00:00行業政策 12月27日,國家衛健委發布《新型抗腫瘤藥物臨床應用指導原則(2021年版)》為規范新型抗腫瘤藥物臨床應用,提高腫瘤治療的合理用藥水平,保障醫療質量和醫療安全,維護腫瘤患者健康權益.
1900/1/1 0:00:00


