






 BTC/HKD-1.25%
BTC/HKD-1.25% ETH/HKD-3.38%
ETH/HKD-3.38% LTC/HKD-2.84%
LTC/HKD-2.84%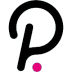 DOT/HKD-3.23%
DOT/HKD-3.23% ADA/HKD-3.57%
ADA/HKD-3.57% SOL/HKD-3.26%
SOL/HKD-3.26% XRP/HKD-4.21%
XRP/HKD-4.21% DOGE/US-4.11%
DOGE/US-4.11%一種針對肺結節的無創多元分析法診斷肺癌
摘要
為了解決常規低劑量CT在肺癌診斷中的假陽性率高的問題,此次研究采用基于血液樣本的無創性檢測來協助臨床醫生進行肺結節診斷的決策的功效。在這項前瞻性觀察性研究中,通過LDCT篩選高危的PNs的患者進行了基于二代測序技術的游離DNA突變分析,基于NGS的cfDNA甲基化分析以及基于血液的蛋白質癌癥生物標志物檢測,然后進行手術切除,并對組織切片進行病理檢查和分類。以病理學分類為金標準,使用統計和機器學習方法基于98位患者的發現隊列選擇與組織惡性分類相關的分子標記,并構建預測組織惡性腫瘤的綜合多分析預測模型。基于各個測試平臺的預測模型表現出不同的性能水平,而它們的最終集成模型AUC為0.85。該模型的性能在29位患者的獨立驗證隊列上得到了進一步證實,其AUC值為0.86,總體敏感性為80%,特異性為85.7%。
引文
低劑量計算機斷層掃描(LDCT)通常用于篩查高危患者的肺癌(LC)。當使用來自基于美國的國家肺篩查試驗的陽性篩查的原始定義時,LDCT性能受到大量陽性調用(27%)的影響,其中96%已被確定為假陽性。隨后的Nelson試驗使用基本上不同的陽性篩查結果定義來將假陽性的比例降低到60%,但這導致LC檢測的敏感度下降了10倍,陽性率為2.7%。由于小的惡性結節的放射學特征不明確,在CT掃描中區分小的惡性結節與良性結節尤其具有挑戰性。因為在中國人群中結核球的患病率相對較高,這使問題變得更加復雜,所以這個問題在作者所在的醫院尤為突出。面對類似的困境,許多臨床上用于廣泛評估癌癥風險的生物標記物缺乏所需的特異性。例如,基于血清蛋白的癌癥生物標志物,如癌癥抗原125(CA125)、癌胚抗原(CEA)、前列腺特異性抗原(PSA)和癌癥抗原19-9(CA199)通常用于監測肺癌患者。但是這些蛋白也在非癌癥患者的血清中被發現,這限制了它們在早期肺癌診斷中的臨床應用。因此,人們一直在尋找特異性更高的生物標志物來補充現有的臨床實踐。循環腫瘤DNA(CtDNA)是基于無細胞DNA(CfDNA)研究的主要腫瘤學研究熱點之一,它為腫瘤特異性基因組改變的無創性研究提供了一個很有前途的平臺。ctDNA研究通常只需要從患者身上提取液體,如血液、胸水、腦脊液等,與傳統的手術活檢方法相比,對實體腫瘤微環境的影響最小,從而避免了應激誘導的腫瘤細胞增殖。下一代測序技術(NGS)的應用,加上先進的計算方法,使得基于ctDNA的腫瘤突變圖譜在廣泛的癌癥類型中得到了極大的應用。有時參考腫瘤組織測序圖譜以指導治療,這些方法已經成功地應用于確診的癌癥患者。與此同時,盡管有許多備受矚目的研究論文,基于血液的突變圖譜在癌癥篩查和早期檢測中的應用仍處于初級階段。這可能是因為當腫瘤很小時,這些突變靶點的等位基因頻率非常低,因此它們對現有技術的可靠檢測構成了挑戰。特別是關于肺癌,Phallen等人,比較早期肺癌和健康人的cfDNA突變譜,報道它們可能是潛在的非侵入性檢測生物標志物。然而,用于區分良惡性肺結節的突變生物標志物的研究報道甚少。DNA序列的全局低甲基化和CpG島(CpG島)的局部高甲基化在腫瘤發生的早期階段被廣泛觀察到,這使得DNA甲基化圖譜成為癌癥早期檢測的一種有吸引力的方法。已經有幾項研究報道了基于血液的肺癌篩查和診斷。Ooki等人,設計了用于早期肺癌檢測的cfDNA甲基化小組,但仍以健康對照為基礎。Hulber等人報道稱,6個基因啟動子區域的甲基化特征對早期肺癌具有較高的診斷準確率。據報道,該技術對中國小結節患者早期非小細胞肺癌的檢測具有很高的敏感性和特異性。梁等人報道的一項臨床研究。研究表明,9種特定的甲基化標記物在區分肺癌和良性肺結節(PN)方面是有效的。這種概念驗證工作在應用于臨床之前通常需要進一步改進,因為該測試的性能與更傳統和更方便的LDCT相當。使用單一技術平臺進行分析的一個突出問題是成像、蛋白質生物標記物、DNA突變或DNA甲基化,這與選擇用于構建預測模型的生物標記物有關。考慮到腫瘤生物學的復雜性,單一的測試平臺很容易對預測模型引入系統性的研究偏差,因為觀察數據只反映了患者/樣本的一個方面。此外,臨床研究經常在有限的隊列規模下面臨現實的挑戰,再加上對潛在預測標記物的巨大搜索空間,結果模型在不同的平臺和研究中表現出巨大的差異并不令人驚訝。自然,對多組學數據的綜合分析可以提供對患者的更全面的看法,減少系統偏差和方差,從而促進更準確的臨床決策。少量研究已經表明結合多組學特征可以提高癌癥篩查的性能。例如,Cohen等人的CancerSeek小組發現基于DNA點突變和蛋白質的腫瘤標志物在區分可切除肺癌和正常標本方面的敏感性和特異性分別達到59%和99%,Silverstri等人的PANOPTIC分類器發現根據蛋白癌生物標志物和患者的臨床特征,可以區分肺結節的良、惡性,敏感性為97%,特異性為44%。我們的研究旨在從兩個方面提升上述技術水平。首先,我們關注的是具有挑戰性的臨床應用,即區分惡性病變和良性病變,而不是腫瘤組織和正常標本。病變是病理改變的組織,無論其惡性程度如何,與正常標本相比,可能具有更高水平的分子特征,因此需要更微妙和更難區分的惡性和良性病變。其次,我們通過整合包括臨床特征、蛋白質生物標志物、cfDNA突變和cfDNA甲基化在內的多種多組學平臺來評估性能改善的水平,以減少系統偏差和方差,從而提高肺PNs的診斷效率。在這個概念驗證階段,我們的目標不是取代廣泛采用的LDCT及其隨后的臨床醫生評審過程,而是提供額外的評估指標來幫助臨床醫生做出決策。考慮到LDCT對假陽性率的限制,我們的目標是提高我們測試的特異性,這樣,當我們的測試結果與LDCT成像一起考慮時,臨床醫生將變得更有信心,將陰性病例排除在隨后不必要的治療之外。
Curve穩定幣crvUSD合約重新部署已完成,套利交易者需更新機器人地址:5月14日消息,Curve Finance發推稱,Curve原生穩定幣crvUSD合約重新部署已完成。此次部署通過套利交易的軟清算進行現場測試,Curve Finance提醒套利交易者更新其機器人地址。[2023/5/15 15:02:43]
結果與討論
我們的研究遵循典型的“監督學習”范式,包括兩個連續的階段。在發現階段,使用統計學和機器學習的方法對發現隊列中樣本的各種臨床和分子特征進行評估,以確定對PN惡性程度有預測意義的潛在標記物。然后構建了預測模型,并對模型進行了參數優化,對模型進行了檢驗。在驗證階段,進一步以獨立的驗證隊列為基準對優化后的預測模型進行基準測試,以評估模型對未知樣本的泛化能力。讀者應該注意到,由于篇幅的限制,以及以臨床實踐人員為目標受眾,我們手稿的其余部分稍微傾向于分析結果對其作出解釋,以及它們在臨床設置中的真實世界含義,而不是數據處理和數據分析的計算方法的算法細節。
研究對象和樣本特征
這項研究包括2019年2月17日至2019年12月10日期間CT篩查出直徑<3cm的肺結節呈陽性并隨后接受手術切除的患者的組織和血漿樣本。所有登記的患者都被要求沒有既往癌癥病史。本研究在手術前抽取了足夠數量的血液樣本,因此需要一個前瞻性的觀察性臨床設置,盡管數據分析是在不影響最初臨床決定的情況下進行的。在發現階段,患者在沒有選擇的情況下被招募和測試,以保證隊列中真實的陽性(惡性)率。在驗證階段,鼓勵LDCT檢測置信度低(即更可能為陰性/良性)的高危患者(基于臨床因素)參加研究,以滿足基于功率分析的隊列大小標準。PN標本的病理評估以手術切除的組織切片為基礎,符合2015年WHO肺癌組織分類標準,所有標本的采集均經陸軍軍醫大學第二附屬醫院倫理委員會批準(項目ID:2019-009-01),所有參與者均提供書面知情同意書。
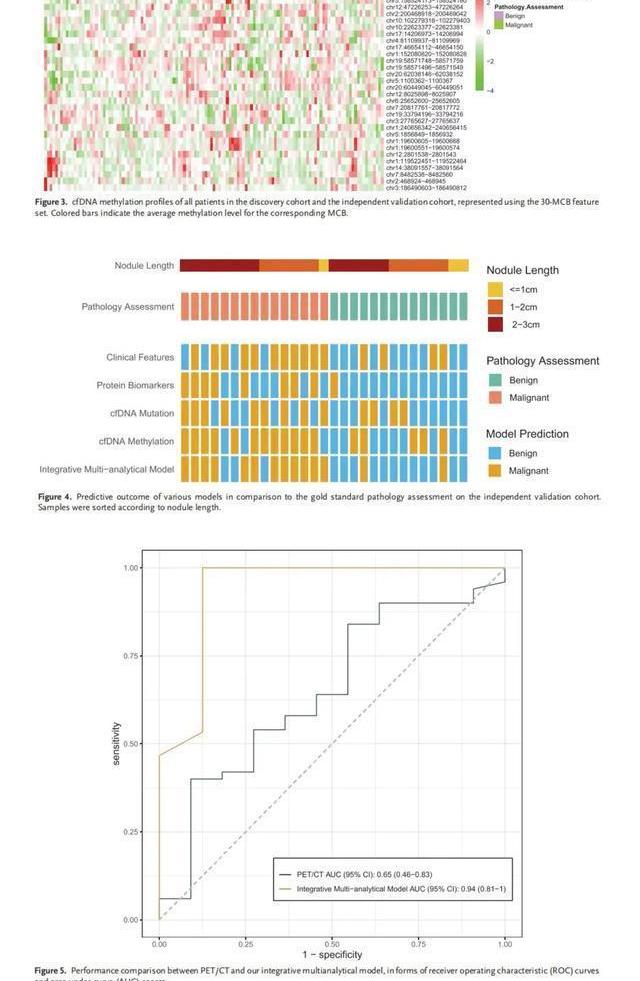
最初收集了99份血漿樣本,并登記在發現隊列中。其中1個樣本因質控不合格而被排除,剩下98個樣本需要進行多分析檢測,其中良性PNS患者28個,惡性PNS患者70個。兩名患者(一名良性,一名惡性)沒有進行蛋白質生物標志物檢測,因此被排除在蛋白質生物標志物發現和綜合多分析模型研究之外。在發現研究之后,一組單獨的29個樣本(14個良性樣本和15個惡性樣本)進入了獨立的驗證隊列(圖1)。在分析接近尾聲時,回顧性登記的樣本還包括57個組織樣本,用于根據選定的甲基化特征位點,評估同一個體的配對組織和血漿之間DNA甲基化特征的一致性。類似地,對55個組織樣本進行了DNA突變測序,以評估與其配對血漿樣本的一致性。
臨床特征與PN惡性程度的相關性及其預測能力
收集患者年齡、性別、吸煙史、飲酒史、腫瘤家族史、結節長度、結節寬度、CT上結節密度等臨床資料。進一步推導了根瘤長度×根瘤寬度和(根瘤長度+根瘤寬度)/2兩種形式的結瘤大小計算公式。表1總結了患者隊列的分布及其臨床特征。
四個結節大小測量結果顯示,在發現隊列中有足夠的統計學意義,其AUC略低于患者年齡,從0.66到0.72不等。然而,當我們使用患者年齡和結節大小特征的不同組合來預測PN惡性腫瘤時,所有模型的表現都比單變量患者年齡模型差。這表明,盡管結節大小可能在群體水平上作為惡性結節和良性結節之間的區別標志,但它本身在個體樣本水平上缺乏預測能力。這可能表明,不是結節的大小,而是結節的細胞組成和分子特征與其惡性程度有更大的關系,因此除了計算機斷層成像分析之外,還需要進行全面的分子研究
多種蛋白質生物標志物綜合分析用于PN惡性程度評估
在新橋醫院測定了臨床癌癥篩查中最常用和最方便獲得的八種蛋白質癌癥生物標志物,即癌癥抗原125(CA125)、癌癥抗原15-3(CA15-3)、癌胚抗原(CEA)、細胞角蛋白-19片段(CYFRA21-1)、神經元特異性烯醇化酶(NSE)、促胃泌素釋放肽前體(PROGRP)、鱗狀細胞癌抗原(SCC)和血清鐵蛋白(SF)。基于化學發光免疫分析(CLIA)平臺,并遵循制造商的標準操作程序(標準操作程序),所使用的試劑盒包括用于CA125的CA125二型試劑盒(雅培公司),CA15-3試劑盒(雅培有限公司KG)用于CA15-3,癌胚抗原試劑盒(雅培愛爾蘭診斷部)用于癌胚抗原,ARCHITECTCYFRA211試劑盒(雅培有限公司KG)用于CYFRA21-1,ARCHITECTProGRP試劑盒(雅培有限公司KG)用于ProGRP,ARCHITECTSCC試劑盒(雅培有限公司KG)用于SCC,鐵蛋白試劑盒(雅培愛爾蘭診斷部)用于SF。最后,神經元特異性烯醇化酶用電化學發光檢測試劑盒(ECLIA,羅氏診斷有限公司)按照標準操作程序進行測定。
數據:疑似Jump Trading地址轉出約3.18萬枚COMP,1.14萬枚轉入Coinbase:金色財經報道,推特用戶@余燼發推表示,疑似Jump Trading所屬地址最近3天轉出了31876枚存放了467天的COMP代幣(約154萬美元),這31876枚COMP代幣在467天前(2021年11月3日)從Coinbase提出并存放在該地址,直到3天前和1小時前分兩批轉出。其中11400枚轉至Coinbase,剩余部分轉入Jump Trading一個中轉地址。[2023/2/14 12:05:42]
基于對發現隊列的單變量分析(表S3a,支持信息),CEA、CYFRA21-1和SCC顯示出統計顯著性(表S4,支持信息),預測AUC分別為0.72、0.68和0.67。使用這三個標記,構建了基于支持向量機(SVM)的多變量預測模型,并在自舉AUC=0.71的發現隊列中進行了測試(圖2a)。
雖然多變量模型的AUC略低于單變量CEA,但我們之前的經驗實驗表明,由于自舉過程中的子采樣,這是一個可接受且可忽略的性能波動,這有時實際上表明模型可能已經達到了相對穩健的局部優化。盡管如此,蛋白質癌癥生物標志物,當單獨或聯合用于預測時,在同一個發現隊列中始終表現不如早期選擇的臨床特征(患者年齡)。雖然這看起來有些令人驚訝,但鑒于眾所周知的蛋白質癌癥生物標志物檢測缺乏特異性,這仍然是可以理解的。
基因突變譜在PN惡性腫瘤分析中的局限性
cfDNA突變測試是在基因科技生物技術有限公司進行的,使用了一個獨特的基于分子標識符(UMI)和基于捕獲的29基因NGS小組(實驗組),通過內部生物信息學管道調用體細胞突變(實驗組)。29基因組的設計是基于與癌癥起源和發展最相關的基因的治療,以及基于公共數據庫的突變流行率,包括癌癥基因組圖譜(TCGA)和癌癥體細胞突變目錄(COSMIC)。根據已建立和驗證的標準進行必要的質量控制檢查和過濾后,發現隊列中每個cfDNA樣本中檢測到的體細胞突變數量從2到47不等,中位數為13,平均值為14.3(表S5,支持信息)。
對個體突變的進一步審查表明,它們在發現隊列中的患病率很低。這可能是由于癌癥起源和演變的復雜性,以及隊列中相當大比例的非癌樣本。這給我們的標記選擇工作帶來了巨大的挑戰,因為通過對發現隊列的單變量分析,沒有突變顯示出統計學意義。
為了解決這個障礙,我們將每個樣本的突變分為四種不同的功能級別,基于它們與公共可用熱點的匹配及其功能注釋(實驗部分),并基于一個假設,即在癌細胞進化過程中,相同功能級別的突變可以近似相等。然后我們用兩個數字特征來表示每個類別,即突變的計數和突變的最大變異等位基因頻率。這個過程將聚集樣本的突變譜組合成八個數字特征(表S5,支持信息)。基于這些特征的建模,SVM在發現隊列中進行的AUC=0.54(圖2a)。
為了了解cfDNA突變譜顯著低效的原因,我們進一步評估了配對腫瘤血漿樣本之間的突變一致性,基于額外的55個腫瘤測序隊列(26個良性和29個惡性)。在29個惡性腫瘤樣本中檢測到的60個突變中,只有1個與相應配對的血漿樣本中檢測到的268個突變一致,而在26個良性腫瘤樣本的31個突變中,只有2個與血漿中的288個突變一致。這表明,在我們的具體應用中,在血漿中檢測到的突變與我們特別感興趣的病變相關的特異性較差,這突出了cfDNA突變分析技術的警告,這不僅是因為該技術的靈敏度有限,還因為癌細胞形成和進化的復雜性。
應用cfDNA甲基化標志物預測PN惡性程度
在GeneCast生物技術有限公司使用基于捕獲的NGS小組進行cfDNA甲基化分析,該小組主要基于公開可獲得的癌癥基因組圖譜(TCGA)數據集設計。使用發現集上的數據(表S6,支持信息),甲基化的CpG位點首先被聚為697個甲基化相關塊(MCB),用于特征表示(實驗部分)。43個MCB在發現隊列中具有統計學意義(表S7,支持信息),其中30個通過機器學習被選為多變量預測因子。
去中心化期權協議Dopex將在Polygon鏈上原生部署Atlantic Straddles:2月4日消息,去中心化期權協議Dopex宣布支持Polygon,將在Polygon鏈上原生部署Atlantic Straddles,Atlantic Stradle作者也將獲得Polygon提供的額外獎勵。[2023/2/4 11:47:06]
綜合多種分析試驗預測PN惡性程度
對所有四個模型對發現隊列的預測進行并列比較,發現在每個樣本上,大多數預測是一致的,但也有一些是不一致的。借用“多數投票”的概念,我們通過隨后的加權平均方法(實驗部分)整合了所有模型的預測輸出。伯努利泊素貝葉斯(BernoulliNaiveBayesian,BNB)學習模型在發現隊列上進行訓練,每個模型的預測輸出作為其輸入,樣本的病理分類作為期望結果。此后,綜合多分析BNB模型在發現隊列上實現了AUC=0.85的顯著改進(圖2a)。
有趣的是,觀察到基于貝葉斯的模型比它的任何組件模型都有更好的表現。雖然患者臨床信息(患者年齡)和蛋白質癌生物標記物平臺顯示的特異性不能令人滿意,而且DNA突變平臺的靈敏度很低,但通過數學集成,它們仍然有助于在DNA甲基化平臺上實現進一步的性能提升,呼應了一句古老的諺語:“兩只手都比一只手好”,并突顯了多組學分子檢測在解決高度復雜的臨床挑戰(如PN惡性評估)中的重要性。然而,對于機器學習方法論研究人員來說,集成模型的改進性能似乎并不令人驚訝。本質上,我們研究中的BNB模型被用作堆疊集成分類器。
以前的研究已經證明,如果第一層輸入分類器具有有限的相關性并相互補充,在我們的情況下,第二層集成分類器將能夠平均來自不同模型的噪聲,從而增強可概括的信號,從而產生更高的準確度。對整合模型的中間權重數據的進一步研究表明,該模型對蛋白質生物標志物(平均值=0.68)和cfDNA突變(0.71)的重要性權重明顯低于對cfDNA甲基化(0.74)和臨床特征(0.76)的重要性權重(圖S3,支持信息),這與我們的研究和以前的報告中每個單獨模型的表現基本一致。
PN惡性標志物和預測模型的獨立驗證
通過每個測試平臺確定的統計標記,以及使用發現隊列上的樣本建立的多變量和多分析模型,我們進一步以29名患者的獨立驗證隊列(14名良性患者和15名惡性患者)為基準。基于最終整合模型的發現隊列的AUC值為0.85時,并假設α為0.05時,對AUC值的顯著性進行統計檢驗的功率分析需要最少的11個良性樣本和11個惡性樣本才能達到0.9%的足夠功率。
單變量臨床特征,患者年齡,在AUC=0.73(圖2b)的驗證隊列(表S1b,支持信息)上總體上保持其預測能力,在截止年齡=54(圖S1,支持信息)的情況下,其敏感性為73.3%,特異性為64.3%。年齡界限在發現隊列中確定,以優化預測模型的性能(以靈敏度+特異度衡量)。
在蛋白質癌癥生物標志物平臺上,三個選定的標志物(分別為CEA、CYFRA21-1和SCC)顯示了獨立驗證群組(可測試的S3b,支持信息)的某些單變量預測能力下降,發現群組的AUC分別從0.72、0.68和0.67下降到驗證群組的0.54、0.52和0.66。然而,他們的聯合多變量預測更穩定,從發現隊列的AUC=0.71到驗證隊列的AUC=0.67(圖2b),使用優化的SVM預測得分截止值0.670,對應于60%的敏感性和71.4%的特異性,并反映出相對于單個蛋白質生物標志物的性能再現性略有改善。值得一提的是,我們觀察到多個蛋白質生物標記的算法組合優于每個單獨的生物標記,這與以前的研究一致,例如用于肺結節管理的Xpressys13-蛋白質分類器,其診斷信息的一致性約為10%(尤登指數)。
發現隊列中受低AUC=0.54影響的cfDNA突變模型在獨立驗證隊列中保持相同的AUC=0.62水平(圖2b;這使得難以平衡預測靈敏度和特異性,使用0.660的優化截止閾值作為預測輸出分數,得到靈敏度=80%和特異性=42.9%。
埃塞俄比亞拒絕銀行用外匯購買“非優先產品”也不要交易加密貨幣:金色財經報道,埃塞俄比亞政府已指示銀行拒絕使用外匯購買財政部所說的非優先商品的請求。為了應對外匯短缺和埃塞俄比亞比爾的貶值,埃塞俄比亞國家銀行于 9 月宣布,它已經下調了埃塞俄比亞旅行者可以帶出境的外匯和當地貨幣的數量。在此之前,央行還建議不要交易加密貨幣。與此同時,埃塞俄比亞工業部長 Melaku Alebel Addis稱,政府最新的外匯限制將無限期地保持有效。(news.bitcoin)[2022/10/19 17:32:24]
cfDNA甲基化模型在驗證群組中也顯示出一定的性能下降,從發現群組的AUC=0.81下降到驗證群組的AUC=0.72(圖2b;測試能力S6b,支持信息),使用0.606的優化預測得分截止值,其轉化為靈敏度=93.3%和特異性=42.9%。然而,這種情況在臨床上被認為是令人滿意的。
為了進一步交叉驗證基于cfDNA的MCB特征,我們對57名同意額外組織測序的發現和驗證隊列中的患者進行了獨立的組織DNA(TDNA)甲基化測序(27例良性和30例惡性;表S8,支持信息),并根據Wilcoxon檢驗評估每個MCB的統計學意義(圖S2a,支持信息)。在大多數MCB上,tDNA圖譜顯示良性和惡性組之間的差異高于cfDNA,這表明這些MCB選擇的是惡性腫瘤的特異性特征。同時,cfDNA圖譜顯示與tDNA的皮爾遜相關系數高達0.84(圖S2B,支持信息),有力地支持了基于cfDNA的MCB測量確實主要來源于他們配對的組織樣本。
最后,盡管每個單獨測試平臺的預測模型的性能波動程度不同,但綜合多分析模型在驗證隊列上的AUC值為0.86時(與發現隊列上的AUC值為0.85時相比)(圖2b),在預測分界值為0.761的情況下,對應的靈敏度=80%和特異度=85.7%,在靈敏度和特異度之間取得了令人滿意的平衡,總體上顯著優于任何單個測試平臺。為了進一步了解綜合模型的預測是如何與每個單獨的模型疊加在一起的,我們將它們在每個驗證上的預測輸出(根據前面提到的優化的截止閾值在良性/惡性方面)與黃金標準的病理評估進行了比較(圖4)。很明顯,在四個個體模型做出相互矛盾預測的大多數樣本(24個樣本中的19個)上,綜合模型能夠更全面地將每個個體模型的輸出組合成與病理評估相匹配的正確預測,證明了前面提到的“兩只手比一只手好”的比喻。
綜合多元分析模型的性能與結節大小的相關性
由于廣泛觀察到血液中循環腫瘤DNA的量與癌癥的階段和腫瘤體積呈正相關,我們根據三個不同的結節長度范圍,即分別<=1、>1<=2和>2<=3,研究了惡性樣品的平均提取的cfDNA量(標準化為全血的ngmL)和整合模型的性能(表S9,支持信息)。
總的來說,我們的數據確實支持了結核大小和結核脫氧核糖核酸數量之間的相關性,發現組群的平均提取的結核脫氧核糖核酸數量分別從551納克/毫升1(1厘米≤1厘米)變為613.35納克/毫升1(1-2厘米)和625.71納克/毫升1(2-3厘米);獨立驗證隊列分別為858、703.33和1015.75納克/毫升。然而,綜合模型的表現,無論是用AUC、靈敏度還是特異性來衡量,盡管顯示出一定程度的波動,但不支持這種正相關性(表S9,支持信息)。雖然可以說這可能是由于我們的研究中隊列規模相對較小,未能揭示明確的統計趨勢,但我們懷疑這也支持了我們早期的觀察,即結節大小(因此cfDNA數量)不是PN惡性腫瘤的強臨床預測因素,這進一步加強了我們的信念,即分子檢測可以提供對PN細胞組成及其惡性腫瘤的更全面的理解,而不是成像本身。此外,我們的綜合多分析分子測試方法已經達到了一個靈敏度水平,通常不受分子大小的影響。這在圖4中也很明顯,其中綜合模型的性能沒有顯示不同結節大小樣本的統計偏差。
綜合多分析模型與正電子發射斷層掃描在結核瘤與惡性結節鑒別中的比較
利用18F-氟脫氧葡萄糖正電子發射斷層掃描/計算機斷層掃描進行分子/解剖成像已被廣泛認為是檢測、識別和分期肺癌的方法。它提供了最大標準攝取值(SUVmax)>2.5的標準攝取值,通常用作區分肺部惡性腫瘤和良性疾病的截止值。作為基線參考,我們研究了一個由61名接受正電子發射斷層掃描/計算機斷層掃描的患者組成的獨立隊列,其中50名后來經病理證實為惡性結節,11名為結核瘤(支持信息,表S10)。惡性結節的SURVAMX一般高于結核瘤(7.18±3.82vs5.36±3.78),但無統計學意義(p=0.264,t=1.147)。值得注意的是,如果僅將SURVAMX用于決策,SURVAMX>2.5的11個結核瘤樣本中有9個將被誤診為惡性,對應于AUC=0.65,靈敏度=90%,特異性=9.1%(圖5)。相比之下,對于我們獨立驗證隊列中患有惡性結節(15)或結核瘤(8)的23名患者,我們的綜合多分析模型的AUC=0.94,敏感性=80%,特異性=87.5%(圖5;和測試S11,支持信息)。盡管這兩組績效指標基于兩個不同的隊列,由于我們隊列中沒有患者進行正電子發射斷層掃描/計算機斷層掃描的限制,并且相對較小的隊列沒有統計學意義,但它們仍然提供了一些有希望的基線理解,說明我們的方法優于正電子發射斷層掃描/計算機斷層掃描。
BitMEX創始人:更多流動性不足公司將出售未鎖定資產,山寨幣可能還會下跌 50% 以上:6月17日消息,BitMEX 創始人 Arthur Hayes 在最新文章中指出,如今許多加密公司以高利率從零售持有者那里借入短期資金,并將其長期鎖定在 DeFi 收益農業策略中。當零售用戶最近要求返還資金時,期限錯配摧毀了這些公司的商業模式。這些公司被迫吐出任何未鎖定在某些長期收益策略中的資產,將發生更多不加選擇地出售其貸款賬簿上所有流動資產的情況,以會將資產返還給他們的零售儲戶。
在接下來的 6 到 12 個月內,法定流動性狀況將是殘酷的,很多對沖基金和其他加密貨幣企業在清盤或嚴重縮減其活動的情況下清算頭寸,這些代幣可能會再下跌 50% 或更多。[2022/6/17 4:33:31]
建議方法的成本和可用性分析
雖然我們的手稿主要集中在建議方法的臨床有效性上,但在我們評估其臨床實用性之前,不應忽視其現實世界的經濟意義。由于我們研究的主要目標是減少對良性肺結節患者的過度治療(不必要的手術),并且我們方法中的抽血比侵入性肺葉切除術或葉下切除術對患者更有吸引力,如果我們聯合分子測試的總貨幣成本低于手術,我們的多組學方法將至少在財務上對特定的良性患者有利(除了所有其他與醫療保健相關的益處)。如果整個受試患者群體的總檢測成本低于所有良性患者的手術成本,我們的方案將在總體臨床上受益。在我們的研究中,基于我們測試的材料和人工成本以及估計的工業利潤,病人的假設測試成本仍然只有手術圍手術期總費用的大約44%(4000美元對9000美元)。盡管如此,這還是基于我們最初實驗設計中用于標記發現的相對較大的NGS面板。一旦我們選擇的少量預測性DNA甲基化MCB標志物和蛋白質癌癥生物標志物在未來的臨床試驗中得到臨床驗證,就有望進一步降低測試成本。因此,我們的方法不僅在臨床上可行,而且在經濟上負擔得起,具有巨大的潛力。
患者花費的第二個方面是時間——以及與之密切相關的測試可用性——他們在等待測試結果和手術的決定。就目前而言,與NGS相關的分子工作臺工作的復雜性幾乎肯定保證了必要的(而不是更容易獲得和更快速的本地現場護理設備),這通常需要至少幾個工作日的周轉時間(TAT)。幸運的是,近年來NGS的技術和物流進步以及分子檢測表明,這種水平的檢測不會成為臨床決策過程中的重大瓶頸,因為外科手術的實際準備時間通常會超過這種檢測。
結論和今后的工作
LDCT的高假陽性率仍然是肺部PNs診斷的一個挑戰,在作者的臨床環境中結核瘤患者的相對高患病率進一步加劇了這一挑戰。我們的研究采用了臨床特征、蛋白質癌癥生物標志物、cfDNA突變和cfDNA甲基化譜來獲得PNs的綜合譜,并建立了一個綜合的多分析模型來從CT診斷肺結節中檢測惡性肺結節。在98名患者的發現隊列中,該模型顯示出區分肺癌患者和良性結節的高鑒別能力(AUC=0.85),在29名患者的驗證隊列中,AUC=0.86進一步得到獨立驗證。綜合模型明顯優于基于任何單獨測試平臺的模型。此外,該模型在結核瘤和惡性肺結節之間的診斷中表現出顯著更好的性能(AUC=0.94),這對于正電子發射斷層掃描來說是一項困難的任務(AUC=0.65)。總之,我們的研究為肺癌的無創診斷提供了一種有效的新方法,并顯示了其在實際臨床應用中的潛力。我們研究的附加價值在肺癌診斷的文獻中已經報道了不同組的cfDNA甲基化標記。例如lian等人的9個cfDNA甲基化位點和chen等人的三基因組合模型,但是后者的靈敏度和特異性隨著結節大小的減小而急劇下降。我們的研究使用基因無關的MCB作為標記。與以前的研究相比,30-MCBs標記集覆蓋了更大的基因組區域,這可能是我們的最終模型無論結節大小如何都保持相對高的敏感性和特異性的原因,因為CpG島胞嘧啶的甲基化沉默了數百個參與肺癌發生和發展的基因。從數據角度來看,由于每個MCB標記都是多個CpG島的合并和算術平均值,因此實踐減少了由于過度擬合而導致的模型方差,并提高了預測模型的穩健性。類似的概念,當應用于cfDNA突變分析時,也顯示了它在處理稀疏、低流行點突變數據方面的有效性。我們的研究可能是第一次將所有臨床特征、蛋白質癌癥生物標志物、cfDNA突變和cfDNA甲基化結合起來,以獲得對PNs更全面的理解,從而實現預測靈敏度和特異性的更好平衡。在我們的研究中,基于貝葉斯的綜合多分析模型優于任何單個模型,并在發現和獨立驗證隊列中保持了相當穩定和平衡的敏感性和特異性。我們的研究清楚地顯示了綜合多組學方法在解決具有挑戰性的臨床應用方面的優勢。未來工作我們的研究有幾個局限性,值得今后的工作。首先,純磨玻璃結節患者不包括在這一階段,這仍是一項未來的工作。第二,我們的模型僅限于經CT篩查的肺結節患者,目的是輔助CT診斷。它在健康人群癌癥篩查中的表現尚待評估。第三,我們的模型用于預測惡性結節和浸潤性癌,其對浸潤前病變(如微創腺癌和原位腺癌)的診斷效果需要進一步驗證。最后,盡管已經在29名患者隊列中進行了獨立驗證,但我們模型的預測性能以及我們方法的有效性仍有待在更大和更多樣化的患者群體中進一步驗證,這項工作已經在進行中,預計將在后續手稿中報告。
實驗部分
大量采集:抽取10mL血液,室溫保存在無細胞DNA存儲管(PET)(cwBiotechCatBillions項目組CWY025M(CwBiotechCatBillions項目組A29319)提取cfDNA。用TIAANAMP血液DNA試劑盒(TIANGEN)從外周血單個核細胞中提取生殖系DNA。DNA和甲基化測序文庫的制備都需要至少10ngcfDNA。采用MagenCatBillions項目組D6323-02B)從惡性和良性FFPE肺組織標本中提取組織基因組DNA(GDNA)。制備甲基化測序文庫至少需要100nggDNA。CfDNA突變分析:cfDNA突變測序基于GeneCast生物技術有限公司實驗室開發的捕獲小組測試,該測試已根據美國病理學家學會(CAP)的指導原則進行了內部驗證。簡而言之,利用KAPAHyperPrepKit(Roche),基于具有唯一分子識別符(UMIS)的接頭,構建了cfDNA突變測序文庫。在接頭連接后,用xGen雜交和洗滌試劑盒(IDT)將DNA雜交到自己設計的124kb大小的29基因突變板上。使用QubitdsDNAHSAssayKit(ThermoFisherCatBillions項目組5634253001)與捕獲板雜交。純化是使用SeqCapEZ純捕獲珠試劑盒(CatBillions項目組Q32854)進行定量。甲基化文庫在IlluminaXten測序系統上測序,閱讀長度為151bp。甲基化數據處理:使用內部管道處理甲基化測序讀數,該管道包含用于解復用的Illuminabcl2fastq、用于基礎質量修整的Trimmomatic、用于參考基因組作圖的Bimark、Bimark、Samtools和用于映射讀數重復數據刪除、排序和剪切的BaMutil(https://github.com/statgen/bamUtil)。映射質量小于20且轉化率小于95%的讀取被過濾掉。CpG位點的甲基化水平被BiSnP以β值的形式稱為。為了進行質量控制,深度小于100倍的CpG位點被去除,支持甲基化閱讀的β值小于2的位點被替換為0。MCB被定義為包含至少3個CpG位點的基因組區域,每個位點與其相鄰位點的距離<=100bp,皮爾遜相關系數>=0.9。分別為發現隊列中的良性和惡性組計算每對相鄰CpG位點之間的相關性。只考慮兩組中相關性高的區塊。根據該標準生成了697個多氯聯苯,包括4678個氯化石蠟位點。MCB中CpG位點的平均β值被用作MCB的甲基化水平。標記物選擇的單變量分析:對于基于臨床特征、癌癥蛋白質生物標記物和cfDNA甲基化MCBs的數據,在發現隊列中進行了六個單變量測試,包括方差分析、費希爾精確測試、卡方測試、威爾科克森秩和測試、曼-惠特尼測試和學生t-測試,以評估每個變量在最大和最小樣本組之間的區分能力。每個測試中p<0.1被認為具有統計學意義。一個變量只有在六個測試中的至少四個測試中具有統計顯著性時,才被視為候選標記。單變量預測AUC也是為參考目的而計算的,但不用作標記物選擇標準。所有單變量測試均使用R版本3.6.3(https://www.R-project.org/)進行。結節惡性腫瘤分類的機器學習:每個數值數據點x首先被標準化為log2(x+1),用于異常值控制和高斯分布近似。缺失的數據點用發現隊列中相應特征讀數的中值估算。數據最終使用z評分進行標準化,z評分計算為z=(X–mean(X))/STD(X),其中X是發現隊列中X的所有讀數。對于甲基化MCB特征,使用交叉驗證遞歸特征消除(RFECV)進行額外的特征選擇,以優化發現隊列模型的準確性。這個過程是通過基于機器學習包scikit-learn的內部Python(3.7版)腳本實現的。每一輪RFECV過程都通過遞歸地從候選特征集中移除排名較低的特征來工作,并通過交叉驗證來評估剩余特征的性能,直到實現優化的性能。通過20個分層的混合分割交叉驗證器,10個分割迭代和20-40%的測試大小范圍,30兆字節的初始篩選43個日期被選擇作為后續培訓的一致特征集。一個基于SVM的分類器在同一個內部Python軟件包中實現,并基于13倍交叉驗證對其性能進行了評估。SVM通過優化預先定義的超平面類型(稱為核)的參數來工作,該超平面將研究中的良性和惡性分類分開,以最大化所有訓練數據點到超平面之間的總距離,換句話說,優化兩個分類的分開。研究中使用了一個簡單的線性核。在每個文件夾中,超參數優化通過交叉驗證網格窮舉搜索進行調整,隨機選擇發現群組中的60%樣本進行訓練,剩余的40%樣本進行測試,并用最佳得分參數重新調整訓練群組。綜合多分析模型:每個個體模型在每個研究領域的預測輸出(即臨床特征、癌癥蛋白標志物、cfDNA突變和cfDNA甲基化)由惡性概率分數組成。這四個分數被用作隨后的BNB模型的輸入,該模型被訓練來優化對每個單獨模型的“投票權”(即,重要性權重)的分配,以便適合每個數據點的已知分類標簽。BNB是一種基于概率論和貝葉斯定理的概率算法,用于預測屬于預定義類別的未知輸入的概率。在lay語言中,由于訓練數據集中每個個體分類器的性能(即,當分類器輸出某個輸出分數時,輸入樣本的惡性被正確預測的概率)是已知的,因此能夠基于所有四個分類器的預測分數的組合導出加權平均公式來計算輸入樣本惡性的概率。該算法是在上述相同的內部Python工具包中實現的。統計分析:由于研究的前瞻性觀察性質,沒有進行統計分析來確定發現隊列的規模,這在很大程度上受樣本可用性的影響。基于預測標記物和模型的性能分析,停止患者登記以進行發現,共同影響整個項目時間表。基于Obuchowski和McCLISH的模型,使用PASS2020軟件的單ROC曲線功率分析模塊進行功率分析,以確定獨立驗證群組的規模。
據報道,比特幣SV在昨天下午晚些時候遭到了所謂的51%攻擊。由于這次襲擊,三個鏈同時被挖掘。CoinMetrics在Twitter上報告了這次攻擊.
1900/1/1 0:00:00反映NFT市場情況的主要指標多集中在外部數據上,這也使得市場關注點多瞄準交易量高,使用人數多、拍賣價高的產品端,從而輕松實現“流量增值”.
1900/1/1 0:00:00北京、上海、長沙等地近期陸續展開新一輪數字人民幣試點活動,數字人民幣正逐漸走進民眾日常生活。北京新一輪數字人民幣試點活動中,20萬中簽幸運兒用上了數字人民幣紅包,在北京冬奧食、住、行、游、購、娛.
1900/1/1 0:00:00幣多多合約量化智能多策略交易系統正式發布,融合一群深耕數字貨幣合約多年的交易技術團隊多年的實戰經驗,經過一個多月的試運營,海量用戶群體注冊參與后,于2021年7月17日在中國深圳正式發布.
1900/1/1 0:00:00電視劇新版《三國》中有這樣一段故事:曹操稱魏王后,公子曹植急赴漳水為其慶祝,倉促強行通過白馬門,被荀彧攔下,雙方發生爭執,后白馬門被曹操強行拆除,并逼荀彧自殺.
1900/1/1 0:00:00SERO系統是全球首創的,基于零知識證明技術實現隱私保護,并且能支持圖靈完備智能合約運行的區塊鏈基礎設施平臺,2.0上線預言機! Sero,超零公鏈 2018年三月研發.
1900/1/1 0:00:00


