






 BTC/HKD+0.09%
BTC/HKD+0.09% ETH/HKD+0.38%
ETH/HKD+0.38% LTC/HKD+0.05%
LTC/HKD+0.05% DOT/HKD-0.13%
DOT/HKD-0.13% ADA/HKD+1.81%
ADA/HKD+1.81% SOL/HKD+0.81%
SOL/HKD+0.81% XRP/HKD+0.21%
XRP/HKD+0.21% DOGE/US+0.77%
DOGE/US+0.77%重點內容:
目前AI + Crypto結合的點主要有2個比較大的方向:分布式算力和ZKML。本文將圍繞去中心化的分布式算力網絡做出分析和反思。
在AI大模型的發展趨勢下,算力資源會是下一個十年的大戰場,也是未來人類社會最重要的東西,并且不只是停留在商業競爭,也會成為大國博弈的戰略資源。未來對于高性能計算基礎設施、算力儲備的投資將會指數級上升。
去中心化的分布式算力網絡在AI大模型訓練上的需求是最大的,但是也面臨最大的挑戰和技術瓶頸。包括需要復雜的數據同步和網絡優化問題等。此外,數據隱私和安全也是重要的制約因素。雖然有一些現有的技術能提供初步解決方案,但在大規模分布式訓練任務中,由于計算和通信開銷巨大,這些技術仍無法應用。
去中心化的分布式算力網絡在模型推理上更有機會落地,可以預測未來的增量空間也足夠大。但也面臨通信延遲、數據隱私、模型安全等挑戰。和模型訓練相比,推理時的計算復雜度和數據交互性較低,更適合在分布式環境中進行。
通過Together和Gensyn.ai兩個初創公司的案例,分別從技術優化和激勵層設計的角度說明了去中心化的分布式算力網絡整體的研究方向和具體思路。
我們在討論分布式算力在訓練時的應用,一般聚焦在大語言模型的訓練,主要原因是小模型的訓練對算力的需求并不大,為了做分布式去搞數據隱私和一堆工程問題不劃算,不如直接中心化解決。而大語言模型對算力的需求巨大,并且現在在爆發的最初階段,2012-2018,AI的計算需求大約每4個月就翻一倍,現在更是對算力需求的集中點,可以預判未來5-8年仍然會是巨大的增量需求。
在巨大機遇的同時,也需要清晰的看到問題。大家都知道場景很大,但是具體的挑戰在哪里?誰能target這些問題而不是盲目入局,才是判斷這個賽道優秀項目的核心。
(NVIDIA NeMo Megatron Framework)
以訓練一個具有1750億參數的大模型為例。由于模型規模巨大,需要在很多個GPU設備上進行并行訓練。假設有一個中心化的機房,有100個GPU,每個設備具有32GB的內存。
數據準備:首先需要一個巨大的數據集,這個數據集包含例如互聯網信息、新聞、書籍等各種數據。在訓練前需要對這些數據進行預處理,包括文本清洗、標記化(tokenization)、詞表構建等。
數據分割:處理完的數據會被分割成多個batch,以在多個GPU上并行處理。假設選擇的batch大小是512,也就是每個批次包含512個文本序列。然后,我們將整個數據集分割成多個批次,形成一個批次隊列。
設備間數據傳輸:在每個訓練步驟開始時,CPU從批次隊列中取出一個批次,然后將這個批次的數據通過PCIe總線發送到GPU。假設每個文本序列的平均長度是1024個標記,那么每個批次的數據大小約為512 * 1024 * 4B = 2MB(假設每個標記使用4字節的單精度浮點數表示)。這個數據傳輸過程通常只需要幾毫秒。
格斗運動員Jon Jones成為NFT系列Kanpai Pandas品牌大使:金色財經報道,曾排名世界第一的美國綜合格斗(MMA)運動員Jon Jones成為NFT系列Kanpai Pandas的品牌大使,還將成為Kanpai Pandas新街頭服飾系列的代言人并進行推廣。(TheBlock)[2023/2/7 11:51:19]
并行訓練:每個GPU設備接收到數據后,開始進行前向傳播(forward pass)和反向傳播(backward pass)計算,計算每個參數的梯度。由于模型的規模非常大,單個GPU的內存無法存放所有的參數,因此我們使用模型并行技術,將模型參數分布在多個GPU上。
梯度聚合和參數更新:在反向傳播計算完成后,每個GPU都得到了一部分參數的梯度。然后,這些梯度需要在所有的GPU設備之間進行聚合,以便計算全局梯度。這需要通過網絡進行數據傳輸,假設用的是25Gbps的網絡,那么傳輸700GB的數據(假設每個參數使用單精度浮點數,那么1750億參數約為700GB)需要約224秒。然后,每個GPU根據全局梯度更新其存儲的參數。
同步:在參數更新后,所有的GPU設備需要進行同步,以確保它們都使用一致的模型參數進行下一步的訓練。這也需要通過網絡進行數據傳輸。
重復訓練步驟:重復上述步驟,直到完成所有批次的訓練,或者達到預定的訓練輪數(epoch)。
這個過程涉及到大量的數據傳輸和同步,這可能會成為訓練效率的瓶頸。因此,優化網絡帶寬和延遲,以及使用高效的并行和同步策略,對于大規模模型訓練非常重要。
需要注意的是,通信的瓶頸也是導致現在分布式算力網絡做不了大語言模型訓練的原因。
各個節點需要頻繁地交換信息以協同工作,這就產生了通信開銷。對于大語言模型,由于模型的參數數量巨大這個問題尤為嚴重。通信開銷分這幾個方面:
數據傳輸:訓練時節點需要頻繁地交換模型參數和梯度信息。這需要將大量的數據在網絡中傳輸,消耗大量的網絡帶寬。如果網絡條件差或者計算節點之間的距離較大,數據傳輸的延遲就會很高,進一步加大了通信開銷。
同步問題:訓練時節點需要協同工作以保證訓練的正確進行。這需要在各節點之間進行頻繁的同步操作,例如更新模型參數、計算全局梯度等。這些同步操作需要在網絡中傳輸大量的數據,并且需要等待所有節點完成操作,這會導致大量的通信開銷和等待時間。
梯度累積和更新:訓練過程中各節點需要計算自己的梯度,并將其發送到其他節點進行累積和更新。這需要在網絡中傳輸大量的梯度數據,并且需要等待所有節點完成梯度的計算和傳輸,這也是導致大量通信開銷的原因。
數據一致性:需要保證各節點的模型參數保持一致。這需要在各節點之間進行頻繁的數據校驗和同步操作,這會導致大量的通信開銷。
雖然有一些方法可以減少通信開銷,比如參數和梯度的壓縮、高效并行策略等,但是這些方法可能會引入額外的計算負擔,或者對模型的訓練效果產生負面影響。并且,這些方法也不能完全解決通信開銷問題,特別是在網絡條件差或計算節點之間的距離較大的情況下。
阿根廷加密交易所Buenbit推出當地貨幣貸款產品,使用DAI作為抵押品:金色財經消息,阿根廷加密貨幣交易所Buenbit推出了一種使用加密貨幣作為抵押品的貸款產品。根據該公司的聲明,該平臺的用戶將能夠使用MakerDAO的穩定幣DAI作為抵押品,并提取最多100萬NuARS,這是一種與阿根廷比索掛鉤的穩定幣。按照目前的匯率,最高金額相當于3,333美元。
該公司CEO Federico Ogue表示,這是一種國外的模式,它們是美元貸款,但美元貸款在拉丁美洲風險太大。(CoinDesk)[2022/7/19 2:21:57]
舉一個例子:
GPT-3模型有1750億個參數,如果我們使用單精度浮點數(每個參數4字節)來表示這些參數,那存儲這些參數就需要~700GB的內存。而在分布式訓練中,這些參數需要在各個計算節點之間頻繁地傳輸和更新。
假設有100個計算節點,每個節點每個步驟都需要更新所有的參數,那么每個步驟都需要傳輸約70TB(700GB*100)的數據。如果我們假設一個步驟需要1s(非常樂觀的假設),那么每秒鐘就需要傳輸70TB的數據。這種對帶寬的需求已經遠超過了大多數網絡,也是一個可行性的問題。
實際情況下,由于通信延遲和網絡擁堵,數據傳輸的時間可能會遠超1s。這意味著計算節點可能需要花費大量的時間等待數據的傳輸,而不是進行實際的計算。這會大大降低訓練的效率,而這種效率上的降低不是等一等就能解決的,而是可行和不可行的差別,會讓整個訓練過程不可行。
就算是在中心化的機房環境下,大模型的訓練仍然需要很重的通信優化。
在中心化的機房環境中,高性能計算設備作為集群,通過高速網絡進行連接來共享計算任務。然而,即使在這種高速網絡環境中訓練參數數量極大的模型,通信開銷仍然是一個瓶頸,因為模型的參數和梯度需要在各計算設備之間進行頻繁的傳輸和更新。
就像開始提到的,假設有100個計算節點,每個服務器具有25Gbps的網絡帶寬。如果每個服務器每個訓練步驟都需要更新所有的參數,那每個訓練步驟需要傳輸約700GB的數據需要~224秒。通過中心化機房的優勢,開發者可以在數據中心內部優化網絡拓撲,并使用模型并行等技術,顯著地減少這個時間。
相比之下,如果在一個分布式環境中進行相同的訓練,假設還是100個計算節點,分布在全球各地,每個節點的網絡帶寬平均只有1Gbps。在這種情況下,傳輸同樣的700GB數據需要~5600秒,比在中心化機房需要的時間長得多。并且,由于網絡延遲和擁塞,實際所需的時間可能會更長。
不過相比于在分布式算力網絡中的情況,優化中心化機房環境下的通信開銷相對容易。因為在中心化的機房環境中,計算設備通常會連接到同一個高速網絡,網絡的帶寬和延遲都相對較好。而在分布式算力網絡中,計算節點可能分布在全球各地,網絡條件可能會相對較差,這使得通信開銷問題更為嚴重。
OpenAI 訓練 GPT-3 的過程中采用了一種叫Megatron的模型并行框架來解決通信開銷的問題。Megatron 通過將模型的參數分割并在多個 GPU 之間并行處理,每個設備只負責存儲和更新一部分參數,從而減少每個設備需要處理的參數量,降低通信開銷。同時,訓練時也采用了高速的互連網絡,并通過優化網絡拓撲結構來減少通信路徑長度。
Uniswap24小時交易量達5300萬美元,交易量前兩名分別是DAI和USDC:Uniswap宣布在此次加密貨幣市場劇烈波動時期,Uniswap24小時交易量達到5300萬美元,交易量前10名的代幣是 DAI、USDC、MRK、SAI、LINK、BAT、WBTC、SNX、KNC和sUSD,這意味著Uniswap通過了壓力測試,證明了Uniswap在處理大量增長的負載是沒有問題的。[2020/3/15]
要做也是能做的,但相比中心化的機房,這些優化的效果很受限。
網絡拓撲優化:在中心化的機房可以直接控制網絡硬件和布局,因此可以根據需要設計和優化網絡拓撲。然而在分布式環境中,計算節點分布在不同的地理位置,甚至一個在中國,一個在美國,沒辦法直接控制它們之間的網絡連接。盡管可以通過軟件來優化數據傳輸路徑,但不如直接優化硬件網絡有效。同時,由于地理位置的差異,網絡延遲和帶寬也有很大的變化,從而進一步限制網絡拓撲優化的效果。
模型并行:模型并行是一種將模型的參數分割到多個計算節點上的技術,通過并行處理來提高訓練速度。然而這種方法通常需要頻繁地在節點之間傳輸數據,因此對網絡帶寬和延遲有很高的要求。在中心化的機房由于網絡帶寬高、延遲低,模型并行可以非常有效。然而,在分布式環境中,由于網絡條件差,模型并行會受到較大的限制。
幾乎所有涉及數據處理和傳輸的環節都可能影響到數據安全和隱私:
數據分配:訓練數據需要被分配到各個參與計算的節點。這個環節數據可能會在分布式節點被惡意使用/泄漏。
模型訓練:在訓練過程中,各個節點都會使用其分配到的數據進行計算,然后輸出模型參數的更新或梯度。這個過程中,如果節點的計算過程被竊取或者結果被惡意解析,也可能泄露數據。
參數和梯度聚合:各個節點的輸出需要被聚合以更新全局模型,聚合過程中的通信也可能泄露關于訓練數據的信息。
安全多方計算:SMC在某些特定的、規模較小的計算任務中已經被成功應用。但在大規模的分布式訓練任務中,由于其計算和通信開銷較大,目前還沒有廣泛應用。
差分隱私:應用在某些數據收集和分析任務中,如Chrome的用戶統計等。但在大規模的深度學習任務中,DP會對模型的準確性產生影響。同時,設計適當的噪聲生成和添加機制也是一個挑戰。
聯邦學習:應用在一些邊緣設備的模型訓練任務中,比如Android鍵盤的詞匯預測等。但在更大規模的分布式訓練任務中,FL面臨通信開銷大、協調復雜等問題。
同態加密:在一些計算復雜度較小的任務中已經被成功應用。但在大規模的分布式訓練任務中,由于其計算開銷較大,目前還沒有廣泛應用。
小結一下
以上每種方法都有其適應的場景和局限性,沒有一種方法可以在分布式算力網絡的大模型訓練中完全解決數據隱私問題。
寄予厚望的ZK是否能解決大模型訓練時的數據隱私問題?
動態 | 金冠股份收深交所關注函,要求披露其擬投資MailTime進軍區塊鏈業務的相關信息:9月24日,金冠股份收到深交所關注函,要求說明此前公告中關于移動互聯網有限公司(移互公司)的表述是否存在誤導投資者的情形,說明移互公司擁有的區塊鏈、數字貨幣、大數據及AI技術與公司新能源充電業務的相關性,該合作事項是否存在迎合市場熱點炒作的情形;充分披露公司擬增資MailTime Inc的具體意向性安排。
9月22日,金冠股份發布公告稱,與移互公司于9月21日簽訂《戰略合作框架協議》及《投資意向協議》,雙方擬在區塊鏈、數字貨幣、大數據及AI等領域合作的基礎上,計劃向MailTime簡信團隊的母公司增資并獲得不超過30%的股份。公司本次擬投資入股MailTime Inc的主要目的為開拓區塊鏈、數字貨幣、大數據及AI在新能源有序充電網及泛在電力物聯網的全球市場。在針對投資者提問“會推出電網相關的數字貨幣嗎?”金冠股份董秘回復稱,對于電網相關的數字貨幣,公司正與新的合作方MDT公司探討。[2019/9/24]
理論上ZKP可以用于確保分布式計算中的數據隱私,讓一個節點證明其已經按照規定進行了計算,但不需要透露實際的輸入和輸出數據。
但實際上將ZKP用于大規模分布式算力網絡訓練大模型的場景中面臨以下瓶頸:
計算和通信開銷up:構造和驗證零知識證明需要大量的計算資源。此外,ZKP的通信開銷也很大,因為需要傳輸證明本身。在大模型訓練的情況下,這些開銷可能會變得特別顯著。例如,如果每個小批量的計算都需要生成一個證明,那么這會顯著增加訓練的總體時間和成本。
ZK協議的復雜度:設計和實現一個適用于大模型訓練的ZKP協議會非常復雜。這個協議需要能夠處理大規模的數據和復雜的計算,并且需要能夠處理可能出現的異常報錯。
硬件和軟件的兼容性:使用ZKP需要特定的硬件和軟件支持,這可能在所有的分布式計算設備上都不可用。
要將ZKP用于大規模分布式算力網絡訓練大模型,還需要長達數年的研究和開發,同時也需要學術界有更多的精力和資源放在這個方向。
分布式算力另外一個比較大的場景在模型推理上,按照我們對于大模型發展路徑的判斷,模型訓練的需求會在經過一個高點后隨著大模型的成熟而逐步放緩,但模型的推理需求會相應地隨著大模型和AIGC的成熟而指數級上升。
推理任務相較于訓練任務,通常計算復雜度較低,數據交互性較弱,更適合在分布式環境中進行。
(Power LLM inference with NVIDIA Triton)
通信延遲:
在分布式環境中,節點間的通信是必不可少的。在去中心化的分布式算力網絡中,節點可能遍布全球,因此網絡延遲會是一個問題,特別是對于需要實時響應的推理任務。
模型部署和更新:
模型需要部署到各個節點上。如果模型進行了更新,那么每個節點都需要更新其模型,需要消耗大量的網絡帶寬和時間。
聲音 | Edan Yago:Thether有點像DAI:EpiphyteCorp CEO Edan Yago發推表示:“Tether有點像Maker DAI(DAI),由用于發行等效令牌的Bitfinex股票支持。”[2019/4/26]
數據隱私:
雖然推理任務通常只需要輸入數據和模型,不需要回傳大量的中間數據和參數,但是輸入數據仍然可能包含敏感信息,如用戶的個人信息。
模型安全:
在去中心化的網絡中,模型需要部署到不受信任的節點上,會導致模型的泄漏導致模型產權和濫用問題。這也可能引發安全和隱私問題,如果一個模型被用于處理敏感數據,節點可以通過分析模型行為來推斷出敏感信息。
質量控制:
去中心化的分布式算力網絡中的每個節點可能具有不同的計算能力和資源,這可能導致推理任務的性能和質量難以保證。
計算復雜度:
在訓練階段,模型需要反復迭代,訓練過程中需要對每一層計算前向傳播和反向傳播,包括激活函數的計算、損失函數的計算、梯度的計算和權重的更新。因此,模型訓練的計算復雜度較高。
在推理階段,只需要一次前向傳播計算預測結果。例如,在GPT-3中,需要將輸入的文本轉化為向量,然后通過模型的各層(通常為Transformer層)進行前向傳播,最后得到輸出的概率分布,并根據這個分布生成下一個詞。在GANs中,模型需要根據輸入的噪聲向量生成一張圖片。這些操作只涉及模型的前向傳播,不需要計算梯度或更新參數,計算復雜度較低。
數據交互性:
在推理階段,模型通常處理的是單個輸入,而不是訓練時的大批量的數據。每次推理的結果也只依賴于當前的輸入,而不依賴于其它的輸入或輸出,因此無需進行大量的數據交互,通信壓力也就更小。
以生成式圖片模型為例,假設我們使用GANs生成圖片,我們只需要向模型輸入一個噪聲向量,然后模型會生成一張對應的圖片。這個過程中,每個輸入只會生成一個輸出,輸出之間沒有依賴關系,因此無需進行數據交互。
以GPT-3為例,每次生成下一個詞只需要當前的文本輸入和模型的狀態,不需要和其他輸入或輸出進行交互,因此數據交互性的要求也弱。
不管是大語言模型還是生成式圖片模型,推理任務的計算復雜度和數據交互性都相對較低,更適合在去中心化的分布式算力網絡中進行,這也是現在我們看到大多數項目在發力的一個方向。
去中心化的分布式算力網絡的技術門檻和技術廣度都非常高,并且也需要硬件資源的支撐,因此現在我們并沒有看到太多嘗試。以Together和Gensyn.ai舉例:
Together是一家專注于大模型的開源,致力于去中心化的AI算力方案的公司,希望任何人在任何地方都能接觸和使用AI。Together剛完成了Lux Capital領投的20m USD的種子輪融資。
Together由Chris、Percy、Ce聯合創立,初衷是由于大模型訓練需要大量高端的GPU集群和昂貴的支出,并且這些資源和模型訓練的能力也集中在少數大公司。
從我的角度看,一個比較合理的分布式算力的創業規劃是:
Step1. 開源模型
要在去中心化的分布式算力網絡中實現模型推理,先決條件是節點必須能低成本地獲取模型,也就是說使用去中心化算力網絡的模型需要開源(如果模型需要在相應的許可下使用,就會增加實現的復雜性和成本)。比如chatgpt作為一個非開源的模型,就不適合在去中心化算力網絡上執行。
因此,可以推測出一個提供去中心化算力網絡的公司的隱形壁壘是需要具備強大的大模型開發和維護能力。自研并開源一個強大的base model能夠一定程度上擺脫對第三方模型開源的依賴,解決去中心化算力網絡最基本的問題。同時也更有利于證明算力網絡能夠有效地進行大模型的訓練和推理。
而Together也是這么做的。最近發布的基于LLaMA的RedPajama是由Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM和Hazy Research等團隊聯合啟動的,目標是研發一系列完全開源的大語言模型。
Step2. 分布式算力在模型推理上落地
就像上面兩節提到的,和模型訓練相比,模型推理的計算復雜度和數據交互性較低,更適合在去中心化的分布式環境中進行。
在開源模型的基礎上,Together的研發團隊針對RedPajama-INCITE-3B模型現做了一系列更新,比如利用LoRA實現低成本的微調,使模型在CPU(特別是使用M2 Pro處理器的MacBook Pro)上運行模型更加絲滑。同時,盡管這個模型的規模較小,但它的能力卻超過了相同規模的其他模型,并且在法律、社交等場景得到了實際應用。
Step3. 分布式算力在模型訓練上落地
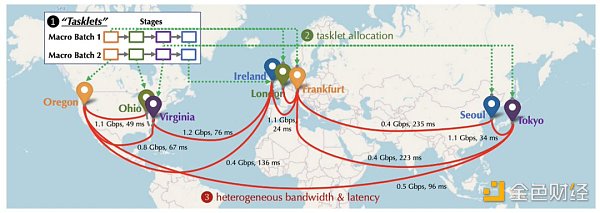
從中長期來看,雖然面臨很大的挑戰和技術瓶頸,承接AI大模型訓練上的算力需求一定是最誘人的。Together在建立之初就開始布局如何克服去中心化訓練中的通信瓶頸方面的工作。他們也在NeurIPS 2022上發布了相關的論文:Overcoming Communication Bottlenecks for Decentralized Training。我們可以主要歸納出以下方向:
調度優化
在去中心化環境中進行訓練時,由于各節點之間的連接具有不同的延遲和帶寬,因此,將需要重度通信的任務分配給擁有較快連接的設備是很重要的。Together通過建立模型來描述特定調度策略的成本,更好地優化調度策略,以最小化通信成本,最大化訓練吞吐量。Together團隊還發現,即使網絡慢100倍,端到端的訓練吞吐量也只慢了1.7至2.3倍。因此,通過調度優化來追趕分布式網絡和中心化集群之間的差距很有戲。
通信壓縮優化
Together提出了對于前向激活和反向梯度進行通信壓縮,引入了AQ-SGD算法,該算法提供了對隨機梯度下降收斂的嚴格保證。AQ-SGD能夠在慢速網絡(比如500 Mbps)上微調大型基礎模型,與在中心化算力網絡(比如10 Gbps)無壓縮情況下的端到端訓練性能相比,只慢了31%。此外,AQ-SGD還可以與最先進的梯度壓縮技術(比如QuantizedAdam)結合使用,實現10%的端到端速度提升。
項目總結
Together團隊配置非常全面,成員都有非常強的學術背景,從大模型開發、云計算到硬件優化都有行業專家支撐。并且Together在路徑規劃上確實展現出了一種長期有耐心的架勢,從研發開源大模型到測試閑置算力(比如mac)在分布式算力網絡用語模型推理,再到分布式算力在大模型訓練上的布局。— 有那種厚積薄發的感覺了:)
但是目前并沒有看到Together在激勵層過多的研究成果,我認為這和技術研發具有相同的重要性,是確保去中心化算力網絡發展的關鍵因素。
從Together的技術路徑我們可以大致理解去中心化算力網絡在模型訓練和推理上的落地過程以及相應的研發重點。
另一個不能忽視的重點是算力網絡激勵層/共識算法的設計,比如一個優秀的網絡需要具備:
確保收益足夠有吸引力;
確保每個礦工獲得了應有的收益,包括防作弊和多勞多得;
確保任務在不同節點直接合理調度和分配,不會有大量閑置節點或者部分節點過度擁擠;
激勵算法簡潔高效,不會造成過多的系統負擔和延遲;
……
看看Gensyn.ai是怎么做的:
成為節點
首先,算力網絡中的solver通過bid的方式競爭處理user提交的任務的權利,并且根據任務的規模和被發現作弊的風險,solver需要抵押一定的金額。
驗證
Solver在更新parameters的同時生成多個checkpoints(保證工作的透明性和可追溯性),并且會定期生成關于任務的密碼學加密推理proofs(工作進度的證明);
Solver完成工作并產生了一部分計算結果時,協議會選擇一個verifier,verifier也會質押一定金額(確保verifier誠實地執行驗證),并且根據上述提供的proofs來決定需要驗證哪一部分的計算結果。
如果solver和verifier出現分歧
通過基于Merkle tree的數據結構,定位到計算結果存在分歧的確切位置。整個驗證的操作都會上鏈,作弊者會被扣除質押的金額。
激勵和驗證算法的設計使得Gensyn.ai不需要在驗證過程中去重放整個計算任務的所有結果,而只需要根據提供的證明對一部分結果進行復制和驗證,這極大地提高了驗證的效率。同時,節點只需要存儲部分計算結果,這也降低了存儲空間和計算資源的消耗。另外,潛在的作弊節點無法預測哪些部分會被選中進行驗證,所以這也降低了作弊風險;
這種驗證分歧并發現作弊者的方式也可以在不需要比較整個計算結果的情況下(從Merkle tree的根節點開始,逐步向下遍歷),可以快速找到計算過程中出錯的地方,這在處理大規模計算任務時非常有效。
總之Gensyn.ai的激勵/驗證層設計目標就是:簡潔高效。但目前僅限于理論層面,具體實現可能還會面臨以下挑戰:
在經濟模型上,如何設定合適的參數,使其既能有效地防止欺詐,又不會對參與者構成過高的門檻。
在技術實現上,如何制定一種有效的周期性的加密推理證明,也是一個需要高級密碼學知識的復雜問題。
在任務分配上,僅僅算力網絡如何挑選和分配任務給不同的solver也需要合理的調度算法的支撐,僅僅按照bid機制來分配任務從效率和可行性上看顯然是有待商榷的,比如算力強的節點可以處理更大規模的任務,但可能沒有參與bid(這里就涉及到對節點availability的激勵問題),算力低的節點可能出價最高但并不適合處理一些復雜的大規模計算任務。
誰需要去中心化算力網絡這個問題其實一直沒有得到驗證。閑置算力應用在對算力資源需求巨大的大模型訓練上顯然是最make sense,也是想象空間最大的。但事實上通信、隱私等瓶頸不得不讓我們重新思考:
去中心化地訓練大模型是不是真的能看到希望?
如果跳出這種大家共識的,“最合理的落地場景”,是不是把去中心化算力應用在小型AI模型的訓練也是一個很大的場景。從技術角度看,目前的限制因素都由于模型的規模和架構得到了解決,同時,從市場上看,我們一直覺得大模型的訓練從當下到未來都會是巨大的,但小型AI模型的市場就沒有吸引力了嗎?
我覺得未必。相比大模型小型AI模型更便于部署和管理,而且在處理速度和內存使用方面更有效率,在大量的應用場景中,用戶或者公司并不需要大語言模型更通用的推理能力,而是只關注在一個非常細化的預測目標。因此,在大多數場景中,小型AI模型仍然是更可行的選擇,不應該在fomo大模型的潮水中被過早地忽視。
區塊律動BlockBeats
曼昆區塊鏈法律
Foresight News
GWEI Research
吳說區塊鏈
西柚yoga
ETH中文
金色早8點
金色財經 子木
ABCDE
0xAyA
Tags:THEETHHERETHER男生ethereal代表什么意義IETH幣pulcher女生突然把網名改成Ethereal
作者:Arthur Hayes 編譯:Lynn,MarsBit(以下所表達的任何觀點都是作者的個人觀點,不應構成投資決策的基礎,也不應被理解為參與投資交易的建議或意見.
1900/1/1 0:00:00作者:Cookie 當以太坊 NFT 圈子被 Azuki Elementals 平地一聲雷地掀起波瀾之時.
1900/1/1 0:00:00據彭博社報道,Digital Currency Group(DCG)將于 5 月 31 日關閉旗下機構交易平臺 TradeBlock,該平臺為機構投資者提供交易執行、定價和大宗經紀服務.
1900/1/1 0:00:00編譯:區塊鏈騎士 Franklin Templeton(富蘭克林鄧普頓基金),全球最大的資產管理公司之一,管理著超過1.5萬億美元的資產,計劃大力投資BTC及其底層技術.
1900/1/1 0:00:00比特幣 2023 會議于 5 月 18 日至 20 日在佛羅里達州邁阿密海灘舉行,參會人數約 1.5 萬人,不足去年 3.5 萬人的一半.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:485.57億美元 DeFi總市值及前十代幣 數據來源:coingecko2、過去24小時去中心化交易所的交易量35.
1900/1/1 0:00:00


