






 BTC/HKD-0.4%
BTC/HKD-0.4% ETH/HKD+0.37%
ETH/HKD+0.37% LTC/HKD-0.23%
LTC/HKD-0.23% DOT/HKD+2.37%
DOT/HKD+2.37% ADA/HKD+1.16%
ADA/HKD+1.16% SOL/HKD+4.32%
SOL/HKD+4.32% XRP/HKD+0.05%
XRP/HKD+0.05% DOGE/US+0.8%
DOGE/US+0.8%撰文:Tanya Malhotra
來源:Marktechpost
編譯:DeFi 之道

圖片來源:由無界版圖AI工具生成
隨著生成性人工智能在過去幾個月的巨大成功,大型語言模型(LLM)正在不斷改進。這些模型正在為一些值得注意的經濟和社會轉型做出貢獻。OpenAI 開發的 ChatGPT 是一個自然語言處理模型,允許用戶生成有意義的文本。不僅如此,它還可以回答問題,總結長段落,編寫代碼和電子郵件等。其他語言模型,如 Pathways 語言模型(PaLM)、Chinchilla 等,在模仿人類方面也有很好的表現。
數據:今年1月初以來,BNB Chain上NFT銷售額增長約1180%:金色財經消息,據BeInCrypto Research的數據,自2022年1月以來,BNB Chain上的NFT銷售額增長了約1180%。1月份,總銷售額大約為94325美元。截止2022年2月,這一數字上升了1109%,達到約114萬美元。在3月18日至3月20日期間,總銷售額攀升至約121萬美元。(BeInCrypto)[2022/3/21 14:09:39]
大型語言模型使用強化學習(reinforcement learning,RL)來進行微調。強化學習是一種基于獎勵系統的反饋驅動的機器學習方法。代理(agent)通過完成某些任務并觀察這些行動的結果來學習在一個環境中的表現。代理在很好地完成一個任務后會得到積極的反饋,而完成地不好則會有相應的懲罰。像 ChatGPT 這樣的 LLM 表現出的卓越性能都要歸功于強化學習。
Samuel Poh擔任KoHo Chain全球戰略顧問:據KoHo Chain官方宣布,Samuel Poh先生已加入KoHo Chain強大的顧問團隊,成為全球戰略顧問。
Samuel Poh將幫助KoHo Chain建立一個穩固的合規基礎,加速KoHo Chain全球化進程。
據悉,Samuel Poh作為前思科全球副總裁,擁有建立、發展、規模化以及領導國際組織的豐富經驗。[2021/5/21 22:29:23]
ChatGPT 使用來自人類反饋的強化學習(RLHF),通過最小化偏差對模型進行微調。但為什么不是監督學習(Supervised learning,SL)呢?一個基本的強化學習范式由用于訓練模型的標簽組成。但是為什么這些標簽不能直接用于監督學習方法呢?人工智能和機器學習研究員 Sebastian Raschka 在他的推特上分享了一些原因,即為什么強化學習被用于微調而不是監督學習。
Riot Blockchain第一季度挖礦收入增長881%至2320萬美元:金色財經報道,在納斯達克上市的礦業公司Riot Blockchain報告稱,第一季度挖礦收入增長了881.1%,達到2,320萬美元。Riot Blockchain報告稱,截至3月31日的三個月期間,挖礦收入利潤率提高至67.5%,去年同期為40.4%。第一季度挖掘了491枚比特幣,比上一季度增長62.0%,2020年第四季度挖掘了303枚比特幣。[2021/5/19 22:17:01]
聲音 | Charlie Lee:LTC八月表現可能不會太好:據zycrypto報道,萊特幣創始人Charlie Lee表示,他并不認為LTC的情況會好轉,特別是在八月。根據Lee的說法,即將到來的LTC區塊獎勵減半可能會導致LTC市場磕磕絆絆,并使其價格下跌。目前,礦工每開采一個區塊就能獲得25 LTC。在減半之后,他們將只能獲得12.5 LTC。對于挖礦設備較少的人來說,意味著回報較低或甚至可能沒有利潤,并使他們退出挖礦業務。[2019/7/12]
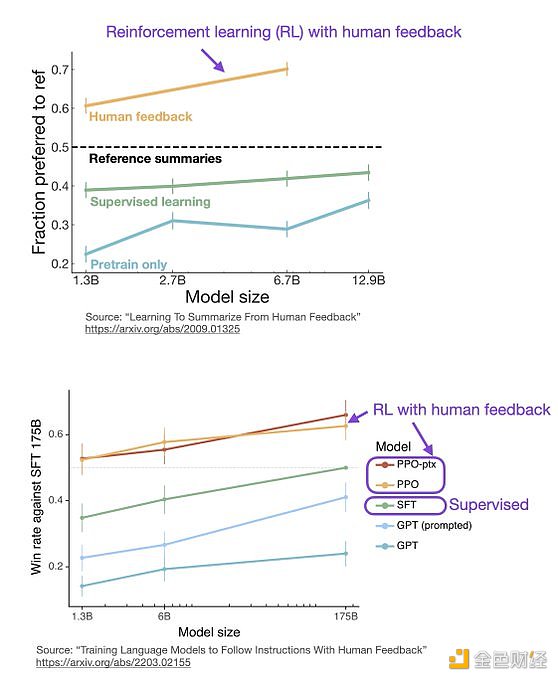
不使用監督學習的第一個原因是,它只預測等級,不會產生連貫的反應;該模型只是學習給與訓練集相似的反應打上高分,即使它們是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量,而不僅僅是排名分數。
Sebastian Raschka 分享了使用監督學習將任務重新表述為一個受限的優化問題的想法。損失函數結合了輸出文本損失和獎勵分數項。這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題-答案對時才能成功。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話也是必要的,而監督學習無法提供這種獎勵。
不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的。
監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好。2022 年的一篇論文《從人類反饋中學習總結》顯示,RLHF 比 SL 表現得更好。原因是 RLHF 考慮了連貫性對話的累積獎勵,而 SL 由于其文本段落級的損失函數而未能很好做到這一點。
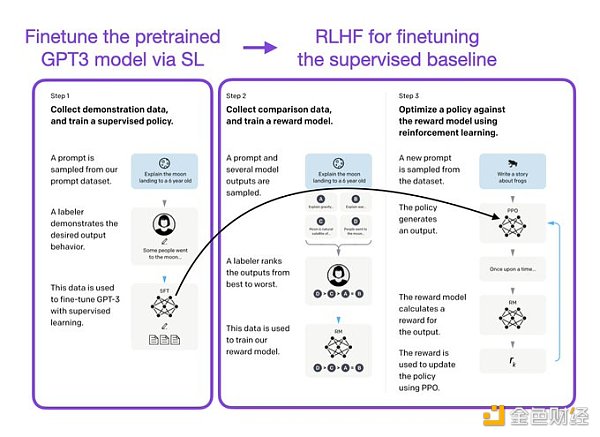
像 InstructGPT 和 ChatGPT 這樣的 LLMs 同時使用監督學習和強化學習。這兩者的結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,然后使用 RL 進一步更新。SL 階段允許模型學習任務的基本結構和內容,而 RLHF 階段則完善模型的反應以提高準確性。
DeFi之道
個人專欄
閱讀更多
金色財經 善歐巴
金色早8點
Odaily星球日報
歐科云鏈
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新聞
Tags:CHAChainHAIAINsdchainFas Chainblockchain官方網站提現CROSSCHAIN
文/Brian Fakhoury,Mechanism Capital合伙人;譯/金色財經xiaozou在Mechanism Capital.
1900/1/1 0:00:00圖片來源:由 Maze AI 工具生成時至今日,Web3 已經吸引了一批技術大牛、金融玩家、風投機構和小部分投機者進入這個「瘋狂的西部」.
1900/1/1 0:00:00游戲歷來被認為是Crypto世界中的核心敘事之一,聚集更多Web2流量、游戲資產所有權、鏈上數據可驗證、全球玩家共同在線、統一貨幣支付等概念無一不切中投資人和用戶的痛點.
1900/1/1 0:00:00不變與變 我不掩飾自己的悲觀,有讀者留言“最近的正能量不多”。原因也很簡單,在時間和空間被拉長和放大的行業里,非常密集的發生著許多坍塌事件,系統性風險里無人幸免.
1900/1/1 0:00:00文/Jack Niewold,Crypto Pragmatist創始人;譯/金色財經xiaozou DeFi 1.0塑造了DeFi的支柱:AAVE、COMP、UNIDeFi 2.0被欺.
1900/1/1 0:00:00談論 Web3 產品時,你首先會聯想到什么?熱點敘事、新技術、經濟模型、去中心化或數據歸屬權....當這些詞語高頻出現時,一個更接近商業本質的詞語似乎被忽略了:收入.
1900/1/1 0:00:00


