






 BTC/HKD-4.84%
BTC/HKD-4.84% ETH/HKD-10.23%
ETH/HKD-10.23% LTC/HKD-10.26%
LTC/HKD-10.26% DOT/HKD-5.35%
DOT/HKD-5.35% ADA/HKD-8.41%
ADA/HKD-8.41% SOL/HKD-7.49%
SOL/HKD-7.49% XRP/HKD-6.31%
XRP/HKD-6.31% DOGE/US-7.55%
DOGE/US-7.55%作者:阿法兔
整理了一下ChatGPT的發展歷程、背后的技術原理,以及它的局限性在哪。(請注意:有部分內容來自于文內的參考資料,如有興趣還請閱讀原文,本文不構成任何投資建議或者對項目的推薦)
ChatGPT是個啥?
近期,OpenAI 發布了 ChatGPT,是一個可以對話的方式進行交互的模型,因為它的智能化,得到了很多用戶的歡迎。ChatGPT 也是OpenAI之前發布的 InstructGPT 的親戚,ChatGPT模型的訓練是使用RLHF(Reinforcement learning with human feedback)也許ChatGPT的到來,也是OpenAI 的GPT-4正式推出之前的序章。
什么是GPT?從GPT-1到GPT-3
Generative Pre-trained Transformer (GPT),是一種基于互聯網可用數據訓練的文本生成深度學習模型。它用于問答、文本摘要生成、機器翻譯、分類、代碼生成和對話 AI。
2018年,GPT-1誕生,這一年也是NLP(自然語言處理)的預訓練模型元年。性能方面,GPT-1有著一定的泛化能力,能夠用于和監督任務無關的NLP任務中。其常用任務包括:
自然語言推理:判斷兩個句子的關系(包含、矛盾、中立)
問答與常識推理:輸入文章及若干答案,輸出答案的準確率
語義相似度識別:判斷兩個句子語義是否相關
分類:判斷輸入文本是指定的哪個類別
雖然GPT-1在未經調試的任務上有一些效果,但其泛化能力遠低于經過微調的有監督任務,因此GPT-1只能算得上一個還算不錯的語言理解工具而非對話式AI。
980枚BTC從Gate.io轉移到未知錢包:金色財經報道,據Whale Alert監測,1小時22分前有980枚BTC(約24,514,487美元)從Gate.io轉移到未知錢包。[2023/6/15 21:38:43]
GPT-2也于2019年如期而至,不過,GPT-2并沒有對原有的網絡進行過多的結構創新與設計,只使用了更多的網絡參數與更大的數據集:最大模型共計48層,參數量達15億,學習目標則使用無監督預訓練模型做有監督任務。在性能方面,除了理解能力外,GPT-2在生成方面第一次表現出了強大的天賦:閱讀摘要、聊天、續寫、編故事,甚至生成假新聞、釣魚郵件或在網上進行角色扮演通通不在話下。在“變得更大”之后,GPT-2的確展現出了普適而強大的能力,并在多個特定的語言建模任務上實現了彼時的最佳性能。
之后,GPT-3出現了,作為一個無監督模型(現在經常被稱為自監督模型),幾乎可以完成自然語言處理的絕大部分任務,例如面向問題的搜索、閱讀理解、語義推斷、機器翻譯、文章生成和自動問答等等。而且,該模型在諸多任務上表現卓越,例如在法語-英語和德語-英語機器翻譯任務上達到當前最佳水平,自動產生的文章幾乎讓人無法辨別出自人還是機器(僅52%的正確率,與隨機猜測相當),更令人驚訝的是在兩位數的加減運算任務上達到幾乎100%的正確率,甚至還可以依據任務描述自動生成代碼。一個無監督模型功能多效果好,似乎讓人們看到了通用人工智能的希望,可能這就是GPT-3影響如此之大的主要原因
GPT-3模型到底是什么?
實際上,GPT-3就是一個簡單的統計語言模型。從機器學習的角度,語言模型是對詞語序列的概率分布的建模,即利用已經說過的片段作為條件預測下一個時刻不同詞語出現的概率分布。語言模型一方面可以衡量一個句子符合語言文法的程度(例如衡量人機對話系統自動產生的回復是否自然流暢),同時也可以用來預測生成新的句子。例如,對于一個片段“中午12點了,我們一起去餐廳”,語言模型可以預測“餐廳”后面可能出現的詞語。一般的語言模型會預測下一個詞語是“吃飯”,強大的語言模型能夠捕捉時間信息并且預測產生符合語境的詞語“吃午飯”。
數據:1.6億枚GALA從Genesis轉移到未知錢包:金色財經報道,據WhaleAlert數據監測,160,000,000枚GALA從Genesis轉移到未知錢包,約合7,263,870美元。[2023/2/13 12:02:43]
通常,一個語言模型是否強大主要取決于兩點:首先看該模型是否能夠利用所有的歷史上下文信息,上述例子中如果無法捕捉“中午12點”這個遠距離的語義信息,語言模型幾乎無法預測下一個詞語“吃午飯”。其次,還要看是否有足夠豐富的歷史上下文可供模型學習,也就是說訓練語料是否足夠豐富。由于語言模型屬于自監督學習,優化目標是最大化所見文本的語言模型概率,因此任何文本無需標注即可作為訓練數據。
由于GPT-3更強的性能和明顯更多的參數,它包含了更多的主題文本,顯然優于前代的GPT-2。作為目前最大的密集型神經網絡,GPT-3能夠將網頁描述轉換為相應代碼、模仿人類敘事、創作定制詩歌、生成游戲劇本,甚至模仿已故的各位哲學家——預測生命的真諦。且GPT-3不需要微調,在處理語法難題方面,它只需要一些輸出類型的樣本(少量學習)。可以說GPT-3似乎已經滿足了我們對于語言專家的一切想象。
注:上文主要參考以下文章:
1.GPT4發布在即堪比人腦,多位圈內大佬坐不住了!-徐杰承、云昭 -公眾號51CTO技術棧- 2022-11-24 18:08
2.一文解答你對GPT-3的好奇!GPT-3是什么?為何說它如此優秀?-張家俊 中國科學院自動化研究所 2020-11-11 17:25 發表于北京
3.The Batch: 329 | InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-07 12:30
GPT-3存在什么問題?
FTX地址從Gearbox移除了約300萬美元的流動性:11月7日消息,PeckShield在推特上表示,0xC098B開頭的FTX地址從DeFi可組合型杠桿協議Gearbox移除了1985枚以太坊(價值約300萬美元)的流動性。[2022/11/7 12:29:08]
但是 GTP-3 并不完美,當前有人們最擔憂人工智能的主要問題之一,就是聊天機器人和文本生成工具等很可能會不分青紅皂白和質量好壞,地對網絡上的所有文本進行學習,進而生產出錯誤的、惡意冒犯的、甚至是攻擊性的語言輸出,這將會充分影響到它們的下一步應用。
OpenAI也曾經提出,會在不久的將來發布更為強大的GPT-4:
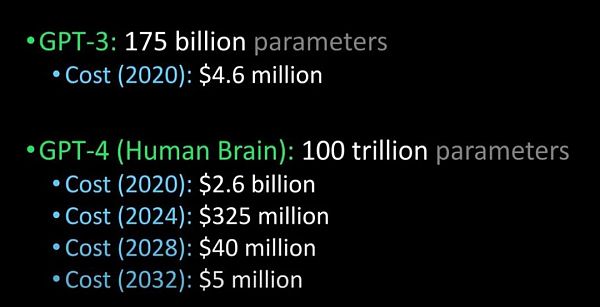
將 GPT-3 與GPT-4、 人腦進行比較(圖片來源:Lex Fridman @youtube)
據說,GPT-4會在明年發布,它能夠通過圖靈測試,并且能夠先進到和人類沒有區別,除此之外,企業引進GPT-4的成本也將大規模下降。
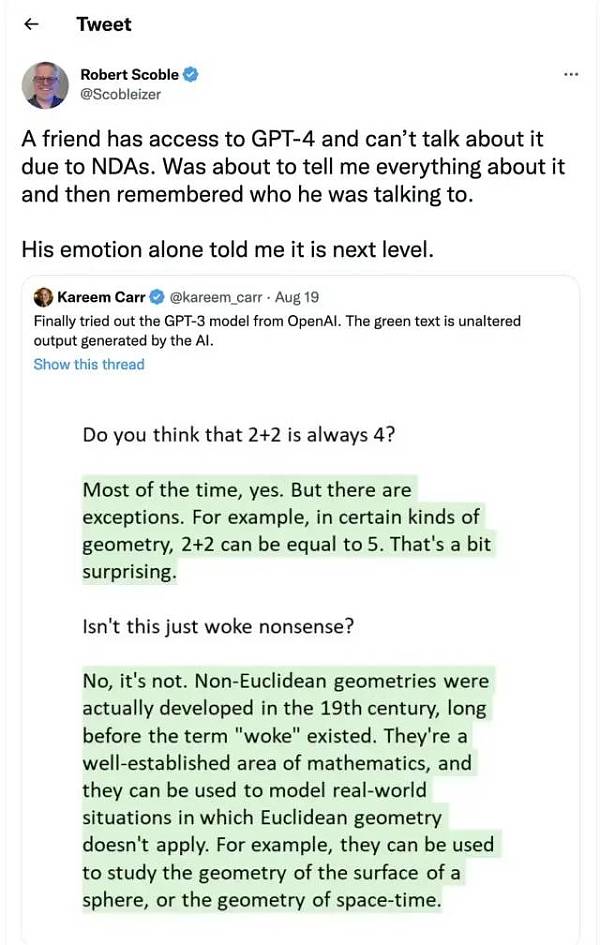
ChatGPT與InstructGPT
談到Chatgpt,就要聊聊它的“前身”InstructGPT。
2022年初,OpenAI發布了InstructGPT;在這項研究中,相比 GPT-3 而言,OpenAI 采用對齊研究(alignment research),訓練出更真實、更無害,而且更好地遵循用戶意圖的語言模型 InstructGPT,InstructGPT是一個經過微調的新版本GPT-3,可以將有害的、不真實的和有偏差的輸出最小化。
數據:998枚BTC從Gemini轉移到Coinbase:金色財經報道,據WhaleAlert數據顯示,998枚BTC從Gemini轉移到Coinbase。[2022/8/25 12:46:42]
InstructGPT的工作原理是什么?
開發人員通過結合監督學習+從人類反饋中獲得的強化學習。來提高GPT-3的輸出質量。在這種學習中,人類對模型的潛在輸出進行排序;強化學習算法則對產生類似于高級輸出材料的模型進行獎勵。
訓練數據集以創建提示開始,其中一些提示是基于GPT-3用戶的輸入,比如“給我講一個關于青蛙的故事”或“用幾句話給一個6歲的孩子解釋一下登月”。
開發人員將提示分為三個部分,并以不同的方式為每個部分創建響應:
人類作家會對第一組提示做出響應。開發人員微調了一個經過訓練的GPT-3,將它變成InstructGPT以生成每個提示的現有響應。
下一步是訓練一個模型,使其對更好的響應做出更高的獎勵。對于第二組提示,經過優化的模型會生成多個響應。人工評分者會對每個回復進行排名。在給出一個提示和兩個響應后,一個獎勵模型(另一個預先訓練的GPT-3)學會了為評分高的響應計算更高的獎勵,為評分低的回答計算更低的獎勵。
開發人員使用第三組提示和強化學習方法近端策略優化(Proximal Policy Optimization, PPO)進一步微調了語言模型。給出提示后,語言模型會生成響應,而獎勵模型會給予相應獎勵。PPO使用獎勵來更新語言模型。
本段參考:The Batch: 329 | InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-07 12:30
重要在何處?核心在于——人工智能需要是能夠負責任的人工智能
動態 | 1238枚BTC從Gemini轉移到OKEx:據Whale Alert鏈上數據監測,北京時間10月11日21:46,1238枚 (10,363,732 USD) 從Gemini轉移到OKEx。交易哈希為c8220d7e92305c27a0ea5459031ad998676fbf119f4a2ae2112906b13e95cfdb。[2019/10/11]
OpenAI的語言模型可以助力教育領域、虛擬治療師、寫作輔助工具、角色扮演游戲等,在這些領域,社會偏見、錯誤信息和害信息存在都是比較麻煩的,能夠避免這些缺陷的系統才能更具備有用性。
Chatgpt與InstructGPT的訓練過程有哪些不同?
總體來說,Chatgpt和上文的InstructGPT一樣,是使用 RLHF(從人類反饋中強化學習)訓練的。不同之處在于數據是如何設置用于訓練(以及收集)的。(這里解釋一下:之前的InstructGPT模型,是給一個輸入就給一個輸出,再跟訓練數據對比,對了有獎勵不對有懲罰;現在的Chatgpt是一個輸入,模型給出多個輸出,然后人給這個輸出結果排序,讓模型去給這些結果從“更像人話”到“狗屁不通”排序,讓模型學習人類排序的方式,這種策略叫做supervised learning,本段感謝張子兼博士)
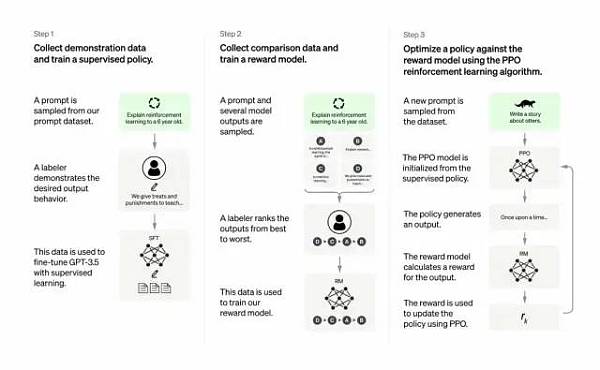
如下:
a) 在訓練的強化學習 (RL) 階段,沒有真相和問題標準答案的具體來源,來答復你的問題。
b) 訓練模型更加謹慎,可能會拒絕回答(以避免提示的誤報)。
c) 監督訓練可能會誤導/偏向模型傾向于知道理想的答案,而不是模型生成一組隨機的響應并且只有人類評論者選擇好的/排名靠前的響應
注意:ChatGPT 對措辭敏感。,有時模型最終對一個短語沒有反應,但對問題/短語稍作調整,它最終會正確回答。訓練者更傾向于喜歡更長的答案,因為這些答案可能看起來更全面,導致傾向于更為冗長的回答,以及模型中會過度使用某些短語,如果初始提示或問題含糊不清,則模型不會適當地要求澄清。
ChatGPT’s self-identified limitations are as follows.
Plausible-sounding but incorrect answers:
a) There is no real source of truth to fix this issue during the Reinforcement Learning (RL) phase of training.
b) Training model to be more cautious can mistakenly decline to answer (false positive of troublesome prompts).
c) Supervised training may mislead / bias the model tends to know the ideal answer rather than the model generating a random set of responses and only human reviewers selecting a good/highly-ranked responseChatGPT is sensitive to phrasing. Sometimes the model ends up with no response for a phrase, but with a slight tweak to the question/phrase, it ends up answering it correctly.
Trainers prefer longer answers that might look more comprehensive, leading to a bias towards verbose responses and overuse of certain phrases.The model is not appropriately asking for clarification if the initial prompt or question is ambiguous.A safety layer to refuse inappropriate requests via Moderation API has been implemented. However, we can still expect false negative and positive responses.
參考文獻:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9aee81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50dd611278a4
3.https://openai.com/blog/chatgpt/
4.GPT4發布在即堪比人腦,多位圈內大佬坐不住了!-徐杰承、云昭 -公眾號51CTO技術棧- 2022-11-24 18:08
5.一文解答你對GPT-3的好奇!GPT-3是什么?為何說它如此優秀?-張家俊 中國科學院自動化研究所 2020-11-11 17:25 發表于北京
6.The Batch: 329 | InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-07 12:30
金色早8點
金色財經
去中心化金融社區
CertiK中文社區
虎嗅科技
區塊律動BlockBeats
念青
深潮TechFlow
Odaily星球日報
騰訊研究院
感謝JS省律師協會金融委邀請,與諸位法律圈朋友分享近期觀察到的金融科技領域的法律問題。一家之言,僅供參考。今天我講的主題是:金融科技行業的法律熱點.
1900/1/1 0:00:00當地時間11月22日周二,FTX 的首次破產聽證會在美國特拉華州舉行,法官簡述了 FTX的崛起和衰落,以及該公司在短短兩周內崩潰的時間線.
1900/1/1 0:00:00撰文:0xmin 最近,印度人成為了全球舞臺上的明星。繼印度人占領硅谷之后,最近,他們又接管了英國。42 歲的蘇納克成為了英國首位印度裔首相,印裔精英不斷出圈.
1900/1/1 0:00:00原文標題:《Post-Merge MEV: Modelling Validator Returns》原文作者:pintail嘗試使用過去的數據來模擬合并后執行層費用對驗證者回報的影響.
1900/1/1 0:00:00原文作者:蔣海波 隨著 Genesis 暴雷、灰度 GBTC 大幅脫鉤,WBTC/BTC 兌換比例也小幅低于 1。在各種不利的外部條件下,FUD 進一步傳播到 WETH.
1900/1/1 0:00:00撰文:Simon Brown編譯:0x11,Foresight NewsMEV 如何成為 PoS 以太坊的中心化力量?本文是對這個問題進行探討的第二部分.
1900/1/1 0:00:00


