






 BTC/HKD+0.66%
BTC/HKD+0.66% ETH/HKD+1.05%
ETH/HKD+1.05% LTC/HKD+0.22%
LTC/HKD+0.22%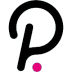 DOT/HKD+0.8%
DOT/HKD+0.8% ADA/HKD+0.79%
ADA/HKD+0.79% SOL/HKD+1.58%
SOL/HKD+1.58% XRP/HKD+0.82%
XRP/HKD+0.82% DOGE/US+0.6%
DOGE/US+0.6%作者:沈旸
全文字數:14000 ???預計閱讀時間:22分鐘
如果說2021年科技圈最火的概念是“元宇宙”,那么2022年最火的一定是Web3.0了。目前看來,較早定義Web3.0概念的,是區塊鏈研究員Eshita。
Web1.0:可讀 Read
Web2.0:可讀+可寫 Read+Write
Web3.0:可讀+可寫+擁有
? ? ?Read+Write+Own
不過,從直觀感覺上來講,這個劃分可能不太準確。畢竟在2004年之前就有大量的BBS、社區和論壇,還有QQ這樣的社交軟件,可以做到信息的讀和寫,讀和寫應該并不是Web1.0和Web2.0的本質區別。今天的頭條新聞和當年的門戶網站看起來都是信息分發,但它們無論是從技術還是業務邏輯上都有本質的區別。
Web3.0的“Own”不代表價值。資產,從定義上來講,就是透過交易或非交易事項,能以貨幣衡量,能夠為個人或企業帶來收益的東西。如果不能變現,不能流通,不能帶來現金流,所有權也沒有價值,一棟坐落于衰退地區的每年需要繳納大額房產稅的房產可能是個負資產。

前段日子在朋友圈看到關于Web1.0到Web3.0的一個調侃,覺得還有點意思,于是結合自己過去的一些經歷,再開了一下腦洞,補充了一下對Web4.0和Web5.0的想象。之后有不少朋友對這個段子感興趣,于是花時間寫下這篇文章,使得段子變得有邏輯,這樣也能讓自己信服未來是美好的,值得努力再奮斗幾十年。
我這個調侃也結合了我自身的經歷,我學過自動化和模式識別,研究過1年的腦機接口項目,然后從事了十多年的信息化、數字化和數據技術相關工作,折騰過一年的區塊鏈和量子應用,在工作之余也對經濟理論比較關注。
不賣關子,先給大家看一下Web1.0到Web5.0的推演過程,然后再詳細展開每個階段的故事。
從Web1.0到Web5.0
——關鍵時刻的預測
Web1.0
1993~2004年,信息的共享和交互
標志性啟動事件:Mosaic瀏覽器的出現,是點燃因特網浪潮的火種之一。
變革原因和對Web2.0的影響:互聯網產生了大量的數據,但是因為技術瓶頸無法盈利。
Web2.0
從2004年開始,數據價值深度挖掘,產生互聯網巨頭
標志性啟動事件:谷歌在2003年后陸續發表關于GFS、MapReduce 和 BigTable的論文。
變革原因和對Web3.0的影響:智能數據的價值深度挖掘,互聯網巨頭開始盈利,并形成壟斷,在智能手機帶來APP數據隔閡,用戶需要更開放和公平的互聯網。互聯網平臺已經深度數字化,孵化了各種大數據和云計算的技術底座。
Web3.0
從2018年開始,數字化的普及和對等價值交換
標志性啟動事件:《通用數據保護條例》(GDPR)的發布。
變革原因和對Web4.0的影響:數據平權和對等價值交換,打破APP的隔閡和互聯網平臺的壟斷,個人和組織的深度數字化,積累可以孵化AI的完備數據畫像,量變引起質變。
Web4.0
預計從2030年開始,意識的交互
標志性啟動事件:面向個人的完備AI助理,通過熟人的“圖靈測試”。
變革原因和對Web5.0的影響:對人類大腦和行為的深度模擬,完成Web5.0需要的智能基礎,人機融合可以進一步解放生產力。
Web5.0
預計從2045年開始,意識的互聯,人機融合
預測標志性啟動事件:人機融合的圖靈測試。
Web1.0:信息共享的時代
在Web1.0時代,誕生了門戶網站、聊天軟件、BBS、電商購物網站等互聯網應用。這個時代最大的特點是聯網和在線,任何線下的場景搬到線上就可以獲得火熱的關注。Web1.0的興起很重要的兩個原因是個人計算機的普及和因特網的大眾化。

由于互聯網用戶增多,產生了巨量的內容和數據,服務器的硬件成本和技術團隊的人工成本急劇上升,互聯網企業壓力巨大。門戶網站的盈利方式主要靠廣告,但是一個網頁的頁面布局空間有限,容納太多廣告的話會影響用戶的體驗。如果不能產生個性化的廣告和精準的推送,從多個客戶賺取廣告費用,那么互聯網公司的營收就無法支撐龐大的基礎架構和技術成本。Web1.0時代的社交軟件也很難把客戶的各種數據保存在服務器端,因為數據的存儲和處理成本過高。
在Web1.0里,大多數互聯網應用只能做到信息的發布、共享和交互,很少能做到更深層的價值挖掘。第一代互聯網在盈利模式上始終是個難題,這個問題導致了第一次互聯網泡沫的破裂。1994~2004年,是第一個互聯網浪潮興起、泡沫和衰退的完整周期。
現場 | 王東臨:區塊鏈改變世界的程度要遠遠超過互聯網:金色財經現場報道,4月10日,YottaChain創始人王東臨在\"2019第二屆深圳國際區塊鏈技術與應用大會”現場以“區塊鏈存儲為什么是風口”為主題進行演講。他表示,區塊鏈確實可以改變世界,而且區塊鏈改變世界的程度,要遠遠超過互聯網改變世界的程度。因為互聯網只是創造了新的商業形態,而區塊鏈不僅創造了新的商業形態,還創造了新的組織形態、經濟形態、社會形態。[2019/4/10]
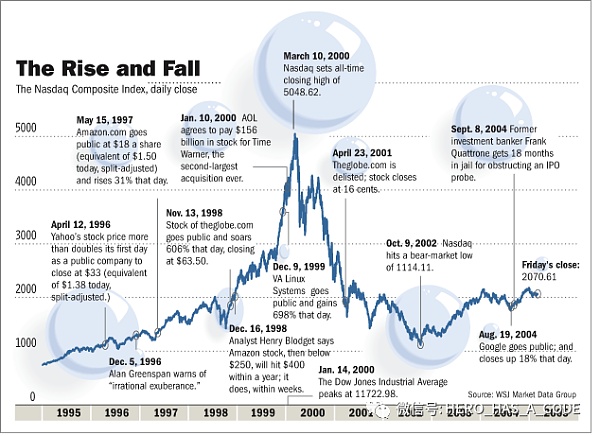
在Web1.0時代,雖然名頭響的是互聯網企業,但是在市值和盈利能力上還是那些企業信息化的IT巨頭們更勝一籌,例如微軟、思科、英特爾、IBM等。互聯網給數據技術帶來的最大挑戰就是數據量極大,但是單位數據的價值不高。企業的應用和業務流程數據往往是抽象和精煉的數據,如果把那些IT巨頭面向的企業級信息化的數據和系統比作工廠在礦山里煉金,那么互聯網的數據處理就像是在河里淘金,這兩個場景需要的技術體系完全不同。互聯網企業需要以極低的成本來收集、存儲和處理數據,然后通過精準的廣告體系來變現。?
延展思考
*?在Web1.0時代,你每天花多少時間上網和線上社交??
Web2.0:數據的大浪淘沙時代,
誕生互聯網巨頭
Web2.0誕生的標志性事件應該就是谷歌在2003年后陸續發表了關于GFS、MapReduce和BigTable的論文,解決了數據存儲、計算和處理的成本問題。谷歌通過內部自研,攻克了互聯網領域的這三座大山。谷歌通過大數據的成本優勢,很早就實現了盈利,并于2004年公開上市。
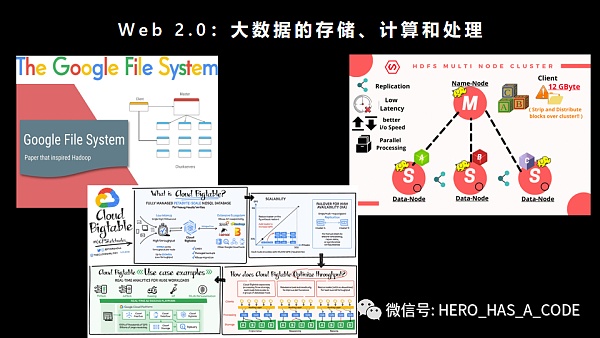
其他的互聯網公司,有些用游戲、短信、甚至一些擦邊球的業務利潤繼續補貼互聯網業務,熬過了沒有大數據技術的艱難時光。后來各互聯網公司通過開源和合作的方式逐漸把谷歌的理論工程化,形成了后來的大數據技術和生態體系,成為互聯網業務的基石。
Web2.0時代是數據、計算和產品的工業化時代,互聯網平臺處理數據的成本越低、效率越高,其壟斷地位就會逐漸形成。過去十幾年里,在搜索、社交、地理服務和信息發布等各個領域,出現了各種各樣的互聯網平臺,這些巨頭利用自身在數據上的技術和規模優勢,不僅僅通過精準廣告實現了數據的價值,也通過數據、流量和場景的結合對傳統行業造成了巨大的挑戰。一些傳統行業公司甚至畏懼與互聯網公司合作,因為擔心自己積累了幾十年的寶貴行業經驗建立的護城河,被互聯網企業通過數據和流量輕松攻破。

有了精準的數據,就可以形成巨大的流量;有了流量,就等于把控了線上的營銷渠道。那些對制造、供應鏈、物流和渠道依賴性不高的產品,在壟斷性的流量前基本沒有還手之力。通過大數據和千人千面的精準建模,互聯網巨頭也開始滲透金融領域,通過金融的杠桿不斷放大業務規模。
海量的個人隱私數據讓一些互聯網平臺得以引導用戶購買特定產品,使得用戶對投放的內容和產品上癮。它們利用大數據殺熟,同樣的商品和服務,多次查看價格會出現變化,老客戶的價格比新客戶更高。它們只推薦能帶來潛在商業利益的產品甚至假冒偽劣產品,而不是對用戶最適合、最恰當的商品。
一些平臺甚至可以利用數據,對個人的欲望、情緒乃至意識形態加以操控,指引用戶閱讀特定文章,為特定人投票或對特定群體產生特定的偏見。它們甚至可以成為特定勢力的代理工具,影響國家大選。即使是大國總統,也可能被互聯網平臺禁言而失去自己的輿論陣地。
在Web2.0,因為智能手機的興起,從網頁時代進入了APP時代,各種弊端表現得尤其明顯。
Web2.0時代一個不公平的現象,是廣大用戶貢獻了互聯網平臺需要的數據,但是雙方的地位并不對等。用戶貢獻了賬戶和數據,但是Web2.0的架構是站在互聯網應用的視角來建設的。對于個人來說,其數據是存在一個個APP的服務器里。當互聯網應用關閉的情況下,用戶的博客、文章、好友列表和關系、聊天記錄都將從互聯網上消失,并且很難被個人用戶在本地長期保存下來。

在基于PC網頁瀏覽器的互聯網時代,各個網站之間還能相互跳轉,相互引用,互聯網用戶還能夠方便地訂閱不同平臺的信息。在APP時代,一些平臺美名其曰ALL IN移動端,大幅砍掉純Web的內容和服務,不登錄不讓看商品目錄,不下載APP就不讓看全文。用戶成了數據運營和流量轉化的工具人,成了各個APP的籠中之物,卻沒有享受到互聯網帶來的開放透明。
在數據安全上,在“不登錄不讓使用”“不同意收集數據不讓使用”等條款下,個人數據被過度采集。互聯網平臺在管理用戶數據的時候,其管理政策和技術過程的披露不夠公開透明,也發生過對內監管不嚴數據被過度使用、對外數據泄露的安全事故。
一些互聯網平臺被用戶貼上了壟斷、霸道、亂用算法的標簽。凡此種種,都違背了互聯網發展的初衷,互聯網用戶期待未來能有一些改變。
聲音 | CryptoOracle聯合創始人:加密技術比互聯網更具破壞性:據CCN消息,CryptoOracle聯合創始人Lou Kerner表示,盡管目前市場處于熊市,但加密技術將是一種比互聯網更具破壞性的技術。虛擬貨幣和區塊鏈最終將證明,其比最初想象的更具革命性。在談及比特幣價格暴跌時,Kerner認為這是因為“不受約束的資本主義讓市場超前了”。[2019/1/1]
*?在Web2.0時代,你清楚自己的數據被怎樣使用么??
Web3.0:數字化的普及
和對等價值交換
為了規范管理互聯網平臺的擴張和對數據的使用,歐洲頒布了《通用數據保護條例》(GDPR),中國也制定了數據安全法。GDPR規定數據主體享有的七項數據權利分別是:訪問權、更正權、刪除權(“被遺忘權”)、限制處理權、可攜帶權、反對權,以及不受制于自動化決策的權利。
與此同時,在區塊鏈的分布式和去中心化的哲學思潮的影響下,科技圈也希望用更透明、更公平、更開放、更去中心化和價值連接的方式實現一個全新的互聯網。個體用戶不僅僅在乎數據的權力,也在乎怎樣在新的互聯網架構體系下分享到價值,這就是Web3.0概念的產生。火爆的ICO、加密貨幣、Defi、GameFi、NFT等概念層出不窮,使得Web3.0的概念在媒體、投資圈、技術圈討論火熱。很多人認為Web3.0是下一代顛覆性的互聯網架構,也有很多人認為Web3.0只是一個理念的炒作,很難真正落地,最終只會是一地雞毛。
如果說,Web2.0給用戶帶來的困擾是壟斷、算法不透明和數據濫用,那么Web3.0就需要在分布式、隱私、開源、信任和連接上做到更好,讓互聯網用戶能夠真正分享到Web3.0的好處。在Web2.0時代,即使作品版權歸用戶,但由于流量完全控制在互聯網平臺,用戶很難將自己的作品或者數據變現。所以對Web3.0的定義,信息對等的價值交換取代了“Own”的概念,如果資源不能帶來預期的收益,用戶的所有權無法體現價值。
與互聯網巨頭談對等價值交換,除了法律保障,還得有實力和資源。這里有兩種實現對等關系的途徑。
第一個途徑是把以前的互聯網平臺完全排除在外,通過對等的個體或者是通過限制個體的規模,建立一個獨立的Web3.0的生態體系。類似比特幣那樣的區塊鏈架構是非常完備的體系,對大多數個體也有公平清晰的規則,但是用這樣的架構無法支撐Web3.0的海量用戶和應用場景。
比特幣的架構體系完美得讓人感覺冷血,這個游戲好像是為機器人設計的。在比特幣里最關鍵的兩個因素是能源和算力,二者構成了機器世界的生存基本元素。想象一下,在一個完全是機器人的世界里,機器人依靠能源產生比特幣,也可以用比特幣來交換能源,獲得更多能源和更優算力的機器人,可以輕松淘汰其他機器人。也許區塊鏈大放異彩的時刻,要等到Web5.0時代吧。
如果不使用閉環的區塊鏈架構,很多項目披著Web3.0的外衣,帶有很強的迷惑性,使得大眾難以辨別是非。關于一些亂象,可以參考這篇文章:《Web3.0里的各種亂象:談談StepN和NFT》。
第二個途徑是加強普通企業和個人的數據管理、技術和價值交換的能力,參與原先的體系,與互聯網平臺共舞。借用區塊鏈的哲學思想和技術體系,充分利用現有的技術和法律的保障來構建Web3.0可能更實際一些。到目前為止,GDPR也只是一系列的法規,還沒有具體的技術和產品跟法規一一對應,整個Web3.0的發展和落地應該會比大家想象的要更漫長。如果Web3.0的核心是數據平等和對等價值交換,數據平等是為了更好的和規模化的對等價值交換,那么可以圍繞這兩點來展開各種探索。
Web3.0對個人的影響
大多數企業都已經完成了基礎的數字化建設,通過各種系統很容易追溯到過往的記錄。企業即使是用SaaS應用軟件或者公有云,也會將數據留存在自己的管控范圍內。但是對于個人來講,大多數人除了照片、文檔和各種筆記外,其他的數據都在哪里呢?個人的數字化,并不是一堆照片和文檔的堆積,就像企業級的ERP應用也不只是一堆文件和數據的堆積。
例如個人用戶的手機里有各種銀行和理財的APP,卻很少有一個值得信賴的總賬管家,來幫助自己管理各個賬戶里的交易和數據。雖然個人手機里有幾十個APP,有的APP記錄了自己的跑步數據,有的APP記錄了自己的睡眠數據,有的APP記錄了自己的體重數據,但是當你想把這些數據匯總在一起做一個歸因分析的時候,對于非技術人員來講幾乎不可能。
因業務調整,跑步軟件NRC APP從2022年7月8日起停止中國大陸地區服務。雖然用戶可以從NRC APP里導出自己需要的數據,但是裸數據對用戶來講并沒有太大的價值,原始的經緯度的記錄也需要應用才能被用戶理解。當你換一個新的健身APP的時候,是否還能用以前的數據和記錄?
HTTP協議發明者蒂姆·伯納斯-李(Tim Berners-Lee)在1998年提出一個語義網(Semantic Web)概念,它的核心是:通過給互聯網上的文檔(如: HTML文檔)添加能夠被計算機理解的語義(元數據),從而使整個互聯網成為一個通用的信息交換介質。但是在進入APP時代后,互聯網平臺并沒有沿著這個開放的方向發展。
聲音 | 工信部李鳴:希望借助區塊鏈技術完善價值互聯網設施建設:據人民網消息,近日,在2018人民網區塊鏈技術冬季論壇上,工信部電子工業標準化研究院區塊鏈研究室主任李鳴表示,雖然無法把區塊鏈融合到每一個行業中,但可以思考區塊鏈的特點、功能體現的行業方向,比如,學歷證書的溯源、農產品溯源。對此,他提出目前的應用場景主要集中在存證、確權、交易交換、溯源、資產金融化等方面。李鳴希望在2019年看到區塊鏈技術的互聯互通,希望可以借助區塊鏈技術完善價值互聯網設施建設,幫助企業解決信息孤島問題,從而讓區塊鏈的供應鏈能夠連通起來,產生價值交換空間,讓價值在所有鏈條里正常流動。[2018/12/24]
因為不滿互聯網平臺對數據的壟斷,Tim Lee又做過一次嘗試,在2018年發布了Solid的去中心化平臺,這并不是一個區塊鏈平臺,https://solid.mit.edu/。Solid的設計思路是每個人都可以擁有一個數據POD,這個POD可以架設在自家的服務器上,也可以由第三方網站托管。當用戶訪問互聯網應用的時候,數據留在個人的Solid的數據POD上,把互聯網應用、平臺數據和個人數據分開。Solid只是第一步,個人數據保存在POD上,也還需要維持數據的一致性和整合。
當一個用戶想把自己在互聯網平臺的文章遷移出去,可能會使用beepress或者wxsync這樣的插件工具把文章同步到自己部署的開源Wordpress系統上。當用戶想收藏整理自己在各種APP里閱讀的內容,可能會用到Cubox這樣的工具。Web2.0時代APP造成的數據墻,使得個人數字化的難度加大了很多,在Web1.0時代很簡單的瀏覽器收藏夾所實現的功能,現在卻需要很多專業的工具才能完成。在Web3.0時代,應該會有更好的工具來幫助個人實現更深層次的數字化,這或許是個不錯的機會點。
大多數成熟的企業都已經建立了數據平臺。在Web3.0時代,個人也需要一個屬于自己的數據管家,用來管理自己所有的數據存儲、分析和交互方式。當APP需要調用數據的時候,由管家來決定哪些數據可以被調用,是否需APP來支付數據調用的成本;當APP產生數據的時候,需要把屬于個人的數據也保存在個人數據管家里;當APP停止運營的時候,需要把個人的數據以方便讀取的方式交給個人數據管家,用另一個開源或者免費的應用來接管這些數據;個人數據管家還可以對多個APP產生的數據進行關聯分析;個人創作的作品,例如文章、視頻等,也是第一時間保存在個人數據管家中,然后通過接口與各個內容分發的平臺進行數據和價值的交換。隨著時間的推移,各種關于個人的數據都將長期保管在個人數據管家之中,形成個人的虛擬印象,最終產生足夠智能的AI數字人,數據積累對AI的孵化,是Web4.0發展的一個重要基礎。
個人數據想要得到價值,必須通過服務或者產品來體現,在Web3.0時代,個人也需要將自己的能力打造成標準的產品,這樣可以更好地進行對等交易。過去幾年,無論是自媒體、公眾號還是短視頻,都有非常多的專家在將自己的價值產品化,逐漸形成清晰的個人畫像。這點上,微信公眾號的Slogan倒是挺符合Web3.0的價值觀。

個人數字化的難點在于:個體的需求具體而清晰,但是每個人的個性和隱私需求可能不同,會不會出現好的工具體系來加速將每一個人數字化呢?
實現Web3.0需要打破APP之間的數據墻
打破互聯網平臺對數據的壟斷也離不開手機廠商對個人隱私的保護。蘋果公司首席執行官蒂姆·庫克在接受《時代》雜志記者采訪時稱:關于我們所有人的信息比十年前或五年前更多,它無處不在,你正在到處留下數字足跡。
假設網絡的速度足夠快、延時足夠低,也許云手機的生態可以加速個人數據管家的誕生。云手機方案可行的話,手機可以只留下電池、屏幕、攝像頭、通信和加密解密的功能,計算、存儲和應用都在云手機上。如果需要硬件升級,可以在后臺實現一鍵升級擴容;如果APP需要升級,可以在虛擬的硬件環境里升級,而不用與復雜的硬件進行兼容測試。
現在的互聯網架構中,有大量應用要用手機號碼注冊,而手機號碼又直接對應個人最隱私的數據——身份證號碼,一旦暴露,將給個人帶來極大影響。而通過云手機里個人數字管家生成的虛擬身份與各種APP對接,可以在真實身份上加一層防護,實現數據更高級別的安全防護,避免隱私的泄露。
云手機也許還可以避免高端手機芯片的封鎖,以彎道超車的方式實現一種新的架構體系。如果云手機的方案能落地,運營商就能從現在數據通道的地位翻身,轉型為未來的數字化主戰場了。由于云手機的技術對帶寬和延時的要求很高,運營商的通信基站和邊緣數據中心能夠形成更好的組合,更能主宰云手機的市場。在運營商主導的云手機體系里,云手機之間的個人數字管家可以實現受監管的自組網,共享分布式數據和應用體系,用來對抗壟斷的互聯網平臺。
Web3.0的網絡鏈接價值
對Web3.0來講,參與其中的個體和企業是對等的關系,在價值交換時需要經過復雜的網絡鏈接,而不僅僅是通過單一的互聯網平臺。
例如,一個企業在做招聘的時候,可以通過帶明確激勵條件的小程序做傳播,每個點擊、傳播和報名的用戶都會通過信息加密記錄下來。經過多次鏈路傳播后,企業可以核對最終錄取者的信息,并把激勵發放給鏈路中間所有的貢獻者。這樣的小程序,雖然不是完備的區塊鏈架構,但是如果企業能夠長期保持其在激勵上的信用,應該是可以替代傳統的網站招聘方式,畢竟企業招聘和幫朋友介紹機會是個雙贏的事情。這樣的方式可以做到精準的信息匹配,在一定程度上也能很好地保護鏈路上用戶的隱私。
聲音 | 周平:區塊鏈的產生不是對互聯網的顛覆:據人民網消息,中國電子技術標準化研究院軟件工程與評估中心主任周平昨日指出,云構建了基礎設施,大數據解決了基礎數據問題,未來經濟需要新型基礎設施,這是屬于區塊鏈的機會。但是,區塊鏈的產生不是對互聯網的顛覆,也不是把互聯網從信息互聯網變為價值互聯網。[2018/10/24]

由于行政區劃與地理遠近并非一致,信息傳遞不能只依行政區劃來安排優先級。比如河南信陽跟湖北武漢一樣愛吃熱干面,它離武漢比離河南省會鄭州更近。如果一個武漢的公司去河南高校招聘,招聘信息傳遞到河南信陽的同鄉群里,得到的反饋可能會比傳遞到普通的畢業班級群里要多得多。但是這樣精準的信息傳遞,需要把信息和價值通過網絡傳播、反饋和驗證,最終才能得到最佳匹配路徑,降低成本,使得企業和個人都受益。
Web3.0時代,并不是要倒退到互聯網的前夜,做事都得靠關系,靠線下的走動;而是要讓這種線下的信息和價值,實現數字化、網絡化并且可傳遞。深網信息挖掘的技術變得更重要,可能強化版的圖數據庫會成為時代的主宰,各種中小型信息數據站點又能夠繁榮發展。
Web3.0對非互聯網企業的影響
在沒有計算機的年代,貨幣就是最好的“數字化”工具,人們用貨幣來衡量社會活動參與個體和企業的經濟價值。
在過去研究的案例中,貝殼是一個把極其傳統的行業和低頻業務做了成功的數字化改造的公司。貝殼數字化成功的很重要的原因,是定義和計算一個業務內的不同組織和環節的價值,邊界清晰,分工專業,實現企業內外協同的市場化和貨幣化,最終實現了業務規模化擴張和平臺生態化。
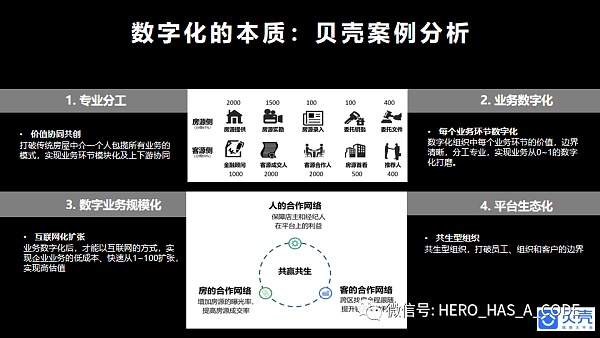
在數字貨幣的技術和規則成熟后,數字貨幣不僅僅可以用于企業對外的業務結算,也適用于企業內部的價值結算,未來每個大型企業都有屬于自身的數字貨幣體系。盡早建立一個企業內部的業務、組織和流程的價值體系,并且不斷與外部的供應商和服務體系進行對比,可以增加外界對企業的各類資源價值的認知確定性。
價值和數字化的結合,打破了企業傳統部門和公司的邊界,清晰的規則,可以幫助企業實現規模的擴張和實現健康的平臺生態。企業可以嘗試用Web3.0的理念,打造行業聯盟或者供應鏈上下游的合作體系,互相開放數據,將跨企業之間的業務數字化,將數字化的普及和對等價值交換的理念做實做深做透,在合作競爭中探索Web3.0的最佳實踐。契約經濟和數字化,不一定非得依靠區塊鏈,用電子合同也可以實現大部分的需求。
企業對數據的管理體系比較成熟。在一些高頻和標準的應用場景中,例如客服等體系,可以引入AI助理,不斷迭代成為企業的虛擬員工。對于低頻和復雜的場景,有些企業已經在部門聊天群里引入AI機器人,不斷學習員工問與答產生的數據,學習企業或者部門的一些特有業務術語和業務邏輯。對于一些商業軟件或者互聯網平臺造成的數據隔閡,也可以使用帶有AI能力的RPA工具將企業的業務流程智能化。
并非每個企業都能擁有互聯網企業那樣的海量數據,在營銷端的數據和流量被互聯網平臺把持的情況下,普通企業可以聚焦在自己的優勢領域,例如生產制造、供應鏈體系、經銷商管理,在供給端做深做透,在每個環節研究數字和價值的深層關系,不用過于焦慮。一味地脫實向虛并不可取,企業不可能靠裸數據來換取價值,數據積累的目的是為了更低成本更高效率的規模交易,交易離不開為實體賦能的產品和服務。社會生產制造消費中有很多智慧和經驗,有的已經迭代成為最佳實踐和第一性原理,其公式對業務的指導有效性,會超過數據的方法論。如果Web3.0真的能實現,在營銷端和流量上,非互聯網企業將不再處于劣勢,那時候比拼的就是供給端的實力了。
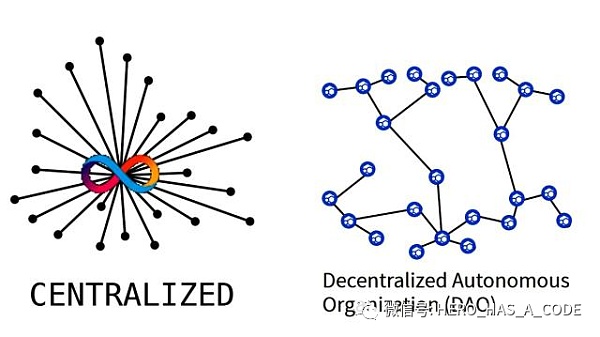
企業與員工之間的關系也可以做Web3.0的探索。大多數情況下,企業相對員工都是處于優勢的地位,因為企業掌握了更多的信息和數據。分布式自治組織(DAO)的概念最早由美國作家奧里·布萊福曼(Ori Brafman)在一本名為《海星和蜘蛛》的書中提出。他在書中將中心化組織比喻為蜘蛛,將分布式組織比喻為海星。
中心化組織在未來也不會消失,有復雜鏈路的業務很難通過去中心化的方式去開展工作。組織是人類社會的最有力的武器之一,有了組織,才能建立龐大復雜的工業體系,才能有登月這樣的偉大創舉。大型企業不太可能完全用分布式自組織的方式進行復雜的生產,但是對于一些新業務,企業可以用阿米巴敏捷小組模式,用DAO的理念進行探索。企業可以用對等價值交換的理念,評估創新業務中員工和企業資源在每個環節中的貢獻,據此不斷孵化出新的業務和組織形態。
在不涉及到企業敏感數據的時候,企業也可以探索在數據治理上企業與員工的關系。企業可能是一個員工消耗時間最多的場所,哪些數據應該歸員工所有?員工在回顧過去經歷的時候是否有完整的畫像?沒有工作中的數據,個人的虛擬印象是不完整的。
企業數字化的難點在于:組織的需求是抽象并且變化的,組織需要長期探索和打磨才能形成適合自己的方法論和體系。
人物丨最高人民檢察院檢察委員會委員萬春:嚴查互聯網金融等重點領域金融犯罪案件:最高人民檢察院檢察委員會委員、法律政策研究室主任萬春:要加大金融案件辦案力度,嚴肅查辦互聯網金融、證券期貨、銀行保險等重點領域、重點環節的金融犯罪案件,加強對新型疑難案件、跨區域涉眾型案件的研究和指導,及時制定司法解釋和規范性文件。[2018/6/25]
Web2.0時代的共享平臺跟Web3.0的區別
在Web2.0時代,也有很多平臺與生態一起共享收益。例如很多電商平臺除了自營業務,也有各類中小賣家;每個司機也是共享打車平臺獨立的“合伙人”,在各個平臺之間進退自如;在內容創作平臺上,創作者也可以獲得平臺的獎勵。是不是這樣的平臺其實已經屬于Web3.0時代了?
這些平臺在價值分享上做到了一定的開放,但是大部分平臺對分潤的模式和算法并不公開透明;另外平臺也沒有考慮參與者的視角,創作者切換平臺有很高的成本。在這點上,開源開放可以使得共享平臺真正走向Web3.0時代。
一些激進的企業,也許可以通過完全開源的方式,比如開源代碼、開放業務模式、開放財務數據、開放非敏感的業務數據,達到透明的信息披露,獲得客戶、員工和投資方更高的信任。例如開源公司Gitlab就把自己的員工手冊和管理方式也開放在互聯網上,這樣全球遠程協同的員工可以更好地融合。
個人非常期待能看到有開源社區能以Web3.0的方式組織起來,開源社區的運作和數據本身就比較公開透明,如果能把平臺、代碼貢獻者、社區參與者和早期用戶的貢獻價值體現在項目中,不斷地平衡過去、現在和未來參與者的貢獻價值,最終將收益返還給所有貢獻者。也許Web3.0的一個標志性事件,就是通過這樣的方式打造成功的項目,并能在傳統交易所上市,獲得公眾的認可。
Web3.0會是一個技術上的倒退么?
1980年代,只有巨頭們擁有大型計算機,但是個人和普通企業很難消費得起。從大型計算機到PC時代,很多人認為是技術上的一個倒退。從各種各樣的性能指標上來講,當年的大型機和小型機都比個人電腦強大很多倍。但是如果時代還停留在大型機時代,那么互聯網的興起就變成不可能的事情。Web1.0時代也是到了后期,通過分布式的集群,云計算的算力才超過傳統的大型機。
40年后的今天,只有大型互聯網平臺才有大量的數據,個人和普通企業只是數據的提供者,而無法充分利用數據時代的紅利。今天大家都能輕松地購買電腦和手機,但是硬件不等于軟件,軟件不等于數據,數據不等于信息,信息不等于價值。很多個人和普通企業的數字化水平,還停留在封閉和碎片化的狀態。
類似GDPR的法規,必然會對互聯網平臺在技術架構體系上產生各種約束,數據的收集、處理、應用和歸檔難度也大幅增加。Web3.0需要的分布式體系,在起步階段的效率,可能不如集中式的Web2.0互聯網平臺。并且Web3.0時代需要的分布式體系,不僅僅是個分布式計算體系,不僅僅是上萬個計算節點組成的云,不僅僅是一個大的分布式數據庫,而是一個由很多個體和組織聯合起來的,分布式、隱私、開源、信任和價值連接的復雜體系。
除了區塊鏈的技術體系外,數字貨幣、電子合同、隱私計算、聯邦身份管理賬戶體系、深網信息挖掘、個人數字管家、AI助理、應用平民化、全員的數字思維、聯盟和上下游共生思維等,都是建立Web3.0體系的重要技術和文化基礎。
也許在一段時間內,Web3.0體現出的技術水平沒法超越Web2.0時代。不過通過Web3.0的建設,個體得以深度數字化,為Web4.0的到來提供了全面的數據基礎。如果沒有數據平等和對等價值交換的基礎,到了Web4.0和Web5.0時代,還是互聯網平臺壟斷一切,其副作用將不可想象。
*?在Web3.0時代,怎樣不被各種概念忽悠??
Web4.0:AI+腦機接口,
意識的交互
AI的發展從量變到質變
世界上第一臺通用計算機“ENIAC”于1946年在美國賓夕法尼亞大學誕生,在計算機誕生后不久,AI與人腦的較量就開始了。計算機科學和密碼學的先驅阿蘭·麥席森·圖靈于1950年寫了一篇論文《計算機器與智能》,文中預言了創造出具有智能的機器的可能性,提出了著名的圖靈測試:如果一臺機器能夠與人類展開對話而不能被辨別出其機器身份,那么稱這臺機器具有智能。圖靈測試是人工智能哲學方面第一個嚴肅的討論。
在2006年之前學習AI的同學可能會感受到,無論用什么算法都很難滿足通用場景。哪怕是現在看起來挺簡單的車牌識別和人臉識別,當時都靠算法工程師調參的手藝,可能在一個特定的場景下可以工作,但是切換到另一個相似的場景就不能滿足要求了。
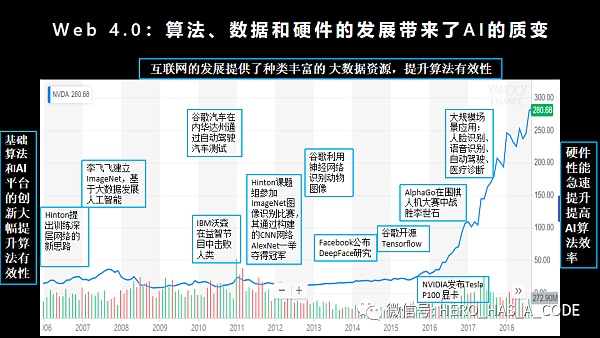
在2006年加拿大多倫多大學教授Hinton提出深度學習的新思路后,人工智能的發展才開始進入快車道。隨著互聯網的發展提供了豐富的大數據資源以及GPU的硬件性能提升,AI的發展終于在2016年迎來了質變。2016年3月,Google旗下的AlphaGo在韓國首爾以總比分4比1的成績戰勝了圍棋世界冠軍、職業九段選手李世石。2017年5月,進化后的AlphaGo在“人機大戰2.0”中,以3:0戰勝世界排名第一的中國選手柯潔。
今天大家覺得AI還比較弱智,無論是家里的智能音箱,還是跟電商的AI客服對話,大家發現AI并不是真的懂自己,無法理解和回答你的很多個性化問題。
這背后的深層原因是現在的大數據積累都是從互聯網平臺視角出發的,而不是從個人用戶視角出發的。
即使互聯網平臺擁有大量的數據,但其在個人的維度上是碎片化和不完整的。由于數據隱私問題,個人也不可能把自己的完整數據交給互聯網平臺。但是可以想象一下,如果個人的數字管家,擁有一個人一生的數字化的記錄,比如收集記錄一個人一生的視頻,每個刺激、反饋和動作,每個閱讀的內容和筆記,每一段對話和思考,那這樣的數據足以訓練AI讀懂一個人。
如果Web3.0真的可以實現,可以想象,個人數字化水平會有飛躍的發展。隨著技術的發展和進步,“個人數字化”的門檻會大幅降低,越來越多的個人數字畫像會被完整記錄,虛擬數字人也會越來越懂個人的需求。
大腦和AI的運作機理類似
科學家和工程師提升計算機的AI水平時,另外一條研究路線也取得了巨大進步,那就是對大腦運作機理的研究。最近讀了一篇非常有意思的文章:《大腦中的熵、自由能、對稱性和動力學》。
人類的大腦在一定程度上是一個貝葉斯模型,生成內部的模型不斷地預測和判斷未來,然后將預測與感官輸入不斷對比,并通過反饋來校驗更新內部的模型。從這個角度來看,現在的AI訓練模式和大腦做的事情非常類似。以德州撲克為例,人類通過觀察自己的起手牌、公共牌、對手的出牌行為和對手的過往歷史記錄,并結合當時對手的表情動作,來做出自己的下注及判斷對手的下一步動作。
德州撲克一直是人工智能領域最難攻克的問題之一,因為撲克對局涉及“隱藏信息”。你不知道對手的牌是什么,也不知道對手對你手牌Range的判斷,要想在牌局中獲勝,需要成功運用bluff 和其他多種策略。這些策略跟國際象棋、圍棋等透明的對局不同,相比較而言,德州撲克面臨的問題更像是真實人類社會生活工作中的真實場景,這使得德州撲克成為AI科學家們最感興趣的領域之一。
在2015年就有德州撲克Solver的概念。與圍棋領域的Alpha Go/Alpha Zero全自動AI算法相比,Solver更像是一個輔助的場外計算器,估算對方手牌的Range以及對方猜測你的手牌的Range。有了這個輔助計算器,人類可以降低計算的復雜度,而把更多的能量放在最終決策上。不過專業的Solver,因為計算量太大,很難在手機里完成實時的計算。
而類似Alpha Go的全自動德州撲克AI算法也取得了很大的成績。Libratus在雙人對決的比賽里獲得了非常好的成績,而Pluribus算法在六人游戲中表現出眾,使用了深度學習算法的Deepstack和Poker CNN也取得了不錯的成績。
德州撲克游戲有一定的特殊性,牌局里有很多隱藏信息,參與的玩家也會受到情緒和體力的影響,牌局的走勢有相當大的隨機干擾。在德州撲克領域靠算法不能保證100%的勝率,AI可能不能完全戰勝人類中最優秀的選手。但是如果一個AI能夠記錄一個人類選手歷史上的所有數據,包括各類身體表情的數據,通過大量的訓練,AI最終應該也能模擬出這個人類選手的出牌風格。在這種情況下訓練出的AI雖然不一定每次都能跟模仿對象出一樣的牌,但是從多輪牌局的統計維度上來看,應該能保持非常好的一致性。
另外人類大腦處理信息大概是在100ms以內完成的,如果AI也能在便攜的計算設備里以相同或者更少的時間做出反饋,那么可以認為AI能夠很好地模擬大腦的工作機制。人類的大腦畢竟不是個無限的信息容器,AI模擬人類在打德州撲克時的風格,應該很快能實現。
AI通過腦機接口讀取人類意識
對大腦的研究除了通過輸入和反饋,也需要對大腦的實體進行深度研究。其中腦機接口就是一項非常實用的技術。目前,大部分的腦機接口就只是對大腦進行讀取信息的操作。
早在1857年,英國青年生理科學工作者卡通(R.Caton)就在猴腦上記錄到了腦電活動,并發表了論文《腦灰質電現象的研究》。1924年,德國的精神病學家貝格爾(H.Berger)真正地記錄到了人腦的腦電波,人的腦電圖從此誕生了。
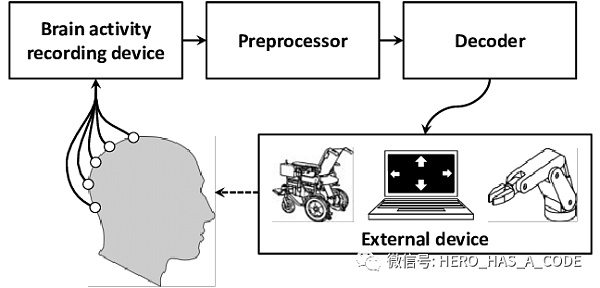
20年前我做腦機接口研究的時候,腦電采集設備還不是很靈敏,為了提高靈敏度,實驗人員甚至可能要剃光頭并涂上導電膠體。常見的實驗場景是,實驗人員戴上腦電采集的電極帽,通過腦電信號和算法,控制屏幕上的鼠標達到指定的區域。在當年大多數公開的記錄中,準確率只能達到75%,在這種情況下,要完成一個字符的輸入可能要花上1分鐘。
最近10年,腦機接口領域的發展突飛猛進。
2021年4月,腦機接口公司Neuralink發布了《Monkey MindPong》的Demo視頻。一只猴子正在靠“意念”輕松地玩電腦游戲。在這個系統里,先是通過正常連接的搖桿來校準系統,然后用腦電的信號輸出和算法來精準模擬有線搖桿的信號;系統校準后,即使是斷開搖桿的連線,猴子也可以靠著腦電的信號輸出來完成游戲。下面的Demo顯示搖桿跟顯示屏之間的連線已經斷開了。不過Neuralink的腦機接口是一種侵入式的系統,需要通過手術將芯片植入到猴子的大腦中,然后通過USB-C接口讀取大腦信號。

2021年5月,斯坦福大學、霍華德?休斯醫學研究所(HHMI)和布朗大學等團隊用腦機接口技術實現了癱瘓患者將腦中的“筆跡”轉化成屏幕字句,并在Nature雜志發表論文《High-performance brain-to-text communication via handwriting》。他們將AI軟件與腦機接口設備結合,利用大腦運動皮層的神經活動解碼“手寫”筆跡,并使用循環神經網絡(RNN)解碼方法,將筆跡實時翻譯成文本,快速將患者對手寫的想法轉換為電腦屏幕上的文本。實驗人員每分鐘可以輸入90個字符,接近正常人在智能手機上的打字速度,這個性能已經非常接近實用場景了,實現了AI讀懂人類大腦中的表達。
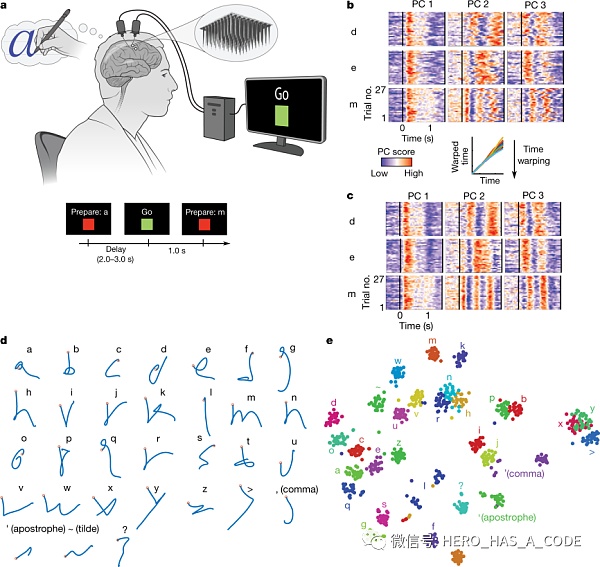
大腦中不斷閃現想法,不一定每個想法都有語言的表達和身體的動作反饋,例如選手在德州牌局正式下注前的掙扎和思考,這些在隱藏層的意識活動對AI的訓練也非常有價值。畢竟人類受到社會和環境的約束,很多想法是無法實現的,尤其是一些重大事件的決策,不是每件事都能下決心和落地的,人的一生做不了太多次重大決策。如果只是把最終表達出的語言和實際落地的行動作為AI訓練的來源,樣本量就會過少,就會遺漏掉那些人性最重要的部分,使得AI無法模擬人類在關鍵時刻的決策。
AI實現對大腦的模擬的3個方向
1.AI對抽象但是簡單的概念進行識別,例如對圖像、聲音等的識別來模擬大腦的功能。
2.通過預測—反饋的不斷測試和復雜的博弈場景,利用全面的個人數據,用AI來擬合人類對各種輸入的反饋。
3.通過對腦機接口的研究,一方面深度挖掘大腦隱藏的工作機制和那些沒能表達出來的想法,塑造更完整的AI;另一方面提供一個很好的人機交互方式,人類可以通過簡單的方式表達自己的意識。
未來,也許人們會隨身戴上便攜式的腦電設備,用以訓練屬于自己的AI助理。無論是游戲還是汽車駕駛,都是非常適合迭代優化個人AI助理的場景。當AI助理足夠了解你的時候,人們就可以復制多份AI助理,用來處理不同的工作,大家就應該可以把更多的時間放在家庭和休閑上了,這時候的AI助理應該稱得上合格吧。
在Web4.0時代,可以實現意識的復制,意識在虛擬空間的交互,還有計算機對大腦意識的讀取。
*?在Web4.0時代,怎樣保護自己的意識被合法使用??
Web5.0:人機融合的時代
也許大家覺得Web5.0的提法有些過于超前,不過很多Web5.0時代的技術,現在都已經在萌芽了。人機融合的定義,借用圖靈測試的標準,就是無論是在網絡的交流中,還是實際的交往中,已經分辨不出是機器還是人了。

首先,我們從仿人機器人開始說起。
在人形機器人領域受關注度最高的玩家要屬波士頓動力公司。2009年,波士頓動力的雙足機器人Petman原型機亮相,此時它需要拖著電纜在履帶上晃晃悠悠地行走。2013年,初具人類外形的Atlas原型機亮相,這時的Atlas已經能夠在碎石堆上行走,還會“金雞獨立”,以及承受大擺球的撞擊。這段視頻發布兩個月后,波士頓動力被谷歌母公司Alphabet收購。2017年,波士頓動力被日本軟銀集團收入囊中。易主并未影響到Atlas的快速成長,它的動作更加流暢,并且能夠上臺階、后空翻等。隨后幾年里,Atlas學會了跑步、體操、翻滾、倒立、跳舞等技能。2021年6月,現代汽車集團與軟銀集團宣布,前者完成了對波士頓動力公司80%股權的收購。
另外一家是特斯拉。繼2021年8月宣布特斯拉人形機器人(Tesla Bot)計劃后,今年6月,馬斯克在推特上表示,將在今年9月30日的特斯拉AI Day推出Tesla Bot原型機。特斯拉人形機器人被命名為Optimus(擎天柱),高1.72米,重56.6千克,與人類相仿,身體由特殊材料制成,內置特斯拉FSD(完全自動駕駛)芯片,并共用AI系統。根據特斯拉的計劃,Optimus最早將于2023年開始生產。在馬斯克看來,從傳感器和執行器的角度來看,制造一個人形機器人是有可能的,目前所缺少的要素有兩點——足夠的智能和擴大的生產規模。
Web4.0的發展和積累剛好可以給機器人帶來足夠的智慧。如果AI機器人對外界的每一個刺激都能做出跟人類一樣的動作和反應,那么在模擬人的方面就算是成功的。
但是機器人的結構與人類肯定會有天壤之別,以機械或者其他材料打造的機器人是無法模擬人類的血肉之軀的,也無法提供人類交流時需要獲得的真實感受。也許聽覺是第一個被AI機器人模擬成功的,然后視覺可以模擬一部分,但是像觸覺、嗅覺、味覺等就很難模擬。正是因為這些難點的存在,所以AI機器人不能在打德州撲克時有爽朗的大笑,和Bluff后緊張的微表情。這些信息和感受對身邊的人類來說同樣重要。
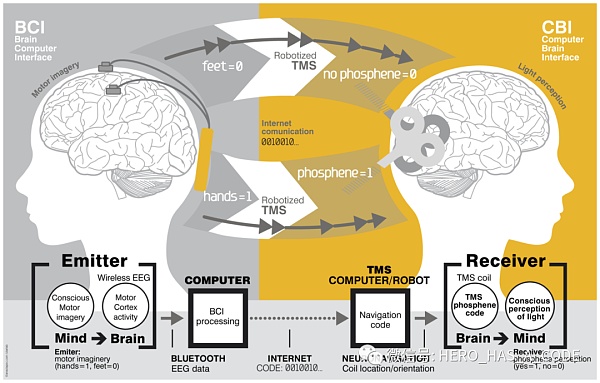
Web4.0階段的腦機接口只是實現從大腦讀取意識,但是在Web5.0階段,腦機接口還需要實現給大腦寫意識的功能,這樣才能真正實現意識的互聯互通。人類的大腦本身就是一個非常好的計算和仿真系統,是一個效率極高的元宇宙體系,私密而又有無窮的可能。在夢境里,人類可以把以前真實見過的、聽說過的、想象過的各類場景和人物重新組合,模擬出全新的場景。這些組合也許符合現實的規律,也許可以超越現實的約束。只需要少量的輸入刺激和引導信號,就可以讓人類的大腦模擬出豐富的場景,類似“盜夢空間”的情景可能就不再是科幻了。
像觸覺、嗅覺、味覺這些機器人很難模擬出來的反饋,也可以通過腦機接口輸入的方式在人類大腦中產生類似的刺激。如果人類無法分辨這個刺激的來源是人類還是互聯的機器AI,那么人機融合的“圖靈測試”應該就可以被認為通過了吧。
*?在Web5.0時代,肉身會被替代么??
后Web5.0時代
也許,“冷血”的區塊鏈體系在人機融合的時代里可以大放異彩,能源和算力成了時代的硬通貨。人類能進入Web3.0,打破互聯網巨頭的壟斷么?人類在Web5.0時代,能與機器共存么?技術進步得越來越快,但是,人類的意識何去何從?人類的肉身何去何從?
三箭資本是最大的加密貨幣對沖基金之一,曾經管理著超過 100 億美元的資本——直到創始人消失。近日,一份長達1000頁的法律文件公布,使案件變得清晰.
1900/1/1 0:00:00特斯拉周三盤后公布了該公司二季度財報。財報顯示,馬斯克變臉了。特斯拉透露,比特幣價格暴跌影響了其第二季度收益,該公司已出售所持約75%比特幣.
1900/1/1 0:00:00原文作者:Raoul Pal,Real Vision CEO原文翻譯:0x137,BlockBeatsRaoul Pal 是全球宏觀金融研究機構 Global Macro Investor 和.
1900/1/1 0:00:00“山寨幣”和“元宇宙”兩詞被收錄進韋氏大詞典:金色財經報道,韋氏大詞典(Merriam-Webster)最近將370個新詞匯加入其中,在添加的新術語中.
1900/1/1 0:00:00現在我們用微信、Discord、推特、Facebook等社交軟件來解決我們在現實世界溝通時遇到的時間和空間的障礙,以最短的時間達成溝通或社交的目的.
1900/1/1 0:00:00英國藝術品拍賣行佳士得正在成立一個風險投資部門,以投資那些讓藝術品交易變得更容易的初創公司,也包括區塊鏈公司.
1900/1/1 0:00:00


