






 BTC/HKD+1.09%
BTC/HKD+1.09% ETH/HKD+1.79%
ETH/HKD+1.79% LTC/HKD+2.45%
LTC/HKD+2.45% DOT/HKD+4.41%
DOT/HKD+4.41% ADA/HKD+1.97%
ADA/HKD+1.97% SOL/HKD+0.92%
SOL/HKD+0.92% XRP/HKD+0.82%
XRP/HKD+0.82% DOGE/US+1.78%
DOGE/US+1.78%大綱
本篇文章目的是通過具體示例,介紹完整的性能項目過程,具體內容介紹區塊鏈性能測試中使用的:1.基本概念2.常用工具3.性能調優的常見情況這3塊內容涵蓋的內容非常多,每一個內容都有很多書籍和文章介紹,詳細的內容不會出現在本文中。基本概念
區塊鏈的性能測試,方法論上與傳統的性能測試沒有不同。性能測試有很多混亂的概念,這里我列出本文描述概念做一些定義。性能測試的定義
性能測試是對系統或者服務的性能指標建立監控策略,在特定場景下執行測試,分析判斷性能瓶頸并調優,最終得出性能結果來評估系統或者服務的性能指標是否滿足既定值。這里結合cosmos-sdk的simapp區塊鏈來解釋。1.需要明確指標,一般指兩類指標:技術指標、業務指標。技術指標一般是TPS,響應時間,資源利用率,對應到區塊鏈一般是指每秒可以處理多少筆交易?這些交易的響應時間或者統計結果是多少?在這種情況下系統使用的資源處于什么狀態?期望滿足的業務指標,應該來源于生產環境統計,以cosmos-sdk的生產應用cosmos-hub為例,其現階段出塊時間大約6秒,每個區塊中的交易數大多數小于10。期望的業務指標設定為TPS為100是較為合理的。。2.測試模型:是真實場景的抽象,描述業務模型是什么樣的。以cosmos-hub為例大致就是,分布在全球的區塊鏈節點,在驗證者節點約500個,活躍驗證者節點約為200的情況下處理交易。測試時可以按比例抽象實際情況。3.測試方案:包括測試環境,測試數據,測試模型,性能指標等。對比區塊鏈系統的測試,就是確定測試架構,準備好如1000個用戶,每個用戶余額1000stake這樣的內容。4.需要有監控:監控的對象有壓力機、區塊鏈節點、其他如負載均衡服務器等。云原生時代的監控一般是Kubernetes+Prometheus+Grafana。5.需要測試條件:硬件環境,測試執行策略等。例如:4C8G,前60秒,每秒增加10個線程。6.需要有場景:指性能場景,正式化的描述是:在既定的環境、既定的數據、既定的執行策略、既定的監控之下,執行性能腳本,同時觀察系統各層級的性能狀態參數變化,并實時判斷分析場景是否符合預期。性能場景,有時被稱為測試用例其實是不對的。7.要有結果報告:報告內容當然就是實際的指標數據。性能場景分類
動態 | 平安集團與深圳市稅務局合作 將利用區塊鏈等技術:據上證報中國證券網消息,1月3日,中國平安保險(集團)股份有限公司(平安集團)與國家稅務總局深圳市稅務局簽署戰略合作框架協議,雙方愿結合自身優勢開展深度合作,利用區塊鏈、人工智能、大數據、云計算等技術,助力深圳市稅務實現“票、財、稅、資”一體化管理、全類別納稅人一站式服務,推動粵港澳大灣區稅務實踐和金融科技融合發展,打造“智慧稅務”全國樣板工程。[2020/1/3]
1.基準性能場景:做單交易/接口的容量,為混合容量做準備。2.容量性能場景:混合容量測試是因為線上真實場景就是由不同的業務組成的,所以由這些業務按照不同并發比例發起梯度壓測就是混合容量測試場景。3.穩定性性能場景:核心就是時長,在長時間的運行之下,觀察系統的性能表現。這個時長的設置,應該來源于運維周期。4.異常性能場景:在強壓力之下,模擬異常。重要的性能指標
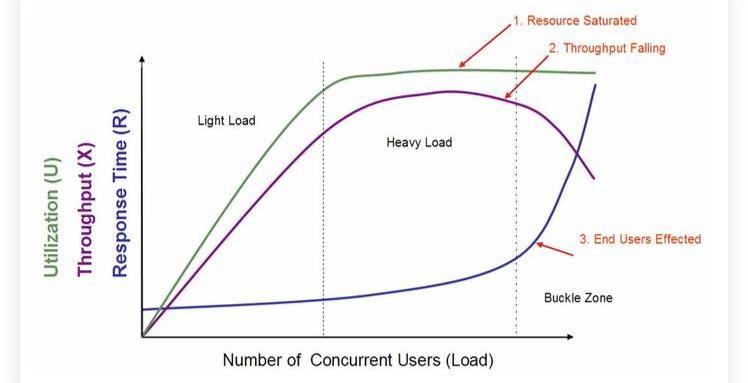
性能測試的指標有很多,比如:1.RT,ResponseTime2.HPS,HitsPerSecond3.TPS,TransactionsPerSecond,這里的Transactions在傳統的應用中一般稱為”事務“,在區塊鏈領域指”交易“4.QPS,QueriesPerSecond5.PV,PageView6.Throughput7.IOPS,Input/OutputOperationsPerSecond比較重要的指標有資源使用率、吞吐量、響應時間,服務提供方比較關心前兩者,用戶更更新后者。關于這些指標的一般情況引用PerformanceTestingMethodology(http://hosteddocs.ittoolbox.com/questnolg22106java.pdf)中的經典圖來說明,實際情況可能不同。圖中定義了3線3區域3狀態,這個圖值得多看看,能夠大致理解指標簡的關系。1.3線:Utilization,Throughput,ResponseTime2.3區域:LightLoad,HeavyLoad,BuckleZone3.3狀態:ResourceSaturated,ThroughputFalling,EndUsersEffected
聲音 | 河北副省長陳剛:雄安將推動區塊鏈等技術與醫療衛生深度融合:據中國經濟網消息,在首屆雄安國際健康論壇上,河北省委常委、副省長、雄安新區黨工委書記陳剛表示,未來雄安新區將建立智慧健康管理體系,推動互聯網、人工智能、區塊鏈等技術與醫療衛生深度融合,形成健康醫療大數據應用體系,建設居民健康平臺,推進智慧醫療。[2018/11/15]
其他
1.一般需要在什么時候做性能測試。a.項目上線前,估計系統承載能力b.項目重構后,評估效果2.如果一個項目得到性能報告就終止,這樣就只是性能驗證。做完全面的性能測試,同時將系統調優到最優狀態,才算是一個完整的性能項目了。性能調優耗時長,還可能需要開發參與,代價高。區塊鏈性能測試區塊鏈的性能測試的指標最重要的是TPS與延遲,a16z的文章Whyblockchainperformanceishardtomeasure對此做了很有洞察的討論,說明了為什么這兩個指標很難測量和比較。其主要內容有以下方面:延遲
延遲的這段時間的起點和終點如何定義?1.起點是用戶點擊提交還是交易到達內存池?2.終點是交易被第1個區塊確認?還是被第6個區塊確認?又或者是最終用戶收到接口響應的時間?3.有些區塊鏈系統對交易會等待一定延遲和到達一定數量才開始處理。這樣比較幸運的就是最后加入的交易,其處理延遲最短。4.對于上訴問題的一種折中方案是,即準確評估整個系統需要考慮延時的分布,而不是將其延遲看做單一數字。5.有些區塊鏈系統的交易處理是有優先級的,fee高的交易很快確認,fee低的相對慢些。fee的不同對交易的延時和TPS的統計是有影響的。吞吐量
金色財經現場報道 陳雪濤:區塊鏈之所以火是因為離錢太近:在GBLS全球無眠區塊鏈領袖峰會上,雷神科技執行董事陳雪濤表示:區塊鏈為什么這么火?因為它離錢太近了,我們看成金融的改革或者叫金融的變革,有人說希望它是金融的革命,現在有的投資人以及專家學者覺得是革命,有的人是變革、有的是改革。總之它離錢太近了。[2018/6/6]
區塊鏈中的吞吐量,即TPS(TransactionPerSecond)來衡量,這里的transaction顯示不是平等的,最簡單的例子就是以太坊中的交易,它可以是轉賬也可以是調用合約。因此,得出TPS需要指定T指代的是什么。另外一個實際的問題是,用戶其實不關心一個區塊鏈的TPS是多少,用戶只關心如何少用fee并盡快完成交易。從這個角度來講,TPS只對系統服務提供商有意義。基本工具
壓力工具
壓力工具一般用Jmeter或者特定應用專用測試工具如下:1.hyperbench/hyperbench2.hyperledger/caliper:Ablockchainbenchmarkframeworktomeasureperformanceofmultipleblockchainsolutions3.https://github.com/xuperchain/xbench4.…使用Jmeter應該是更貼近使用場景,更通用。一般與區塊鏈節點進行交互的方式有1.gRPC協議2.HTTP協議(REST接口)Jmeter支持的Sampler支持有HTTP,對gRPC協議的支持需要借助插件jmeter-grpc-request監控工具
金色財經現場報道 SCRY創始人兼CEO符安文:區塊鏈講概念都是扯淡的:金色財經現場報道,在2018區塊鏈技術及應用峰會上,SCRY創始人兼CEO符安文表示,區塊鏈講概念都是扯淡的,要看能不能落在實際應用上。做區塊鏈的,要擴大整個業務的發展,去幫助實際的產業做交易,讓技術更快地應用于各個產業和行業,中間要解決的一個核心問題是怎么把業務層的數據變成智能合約。此外,純互聯網的系統不能解決數據并發的問題,鏈的下面一定要有分布式的數據庫和容器做擴容,如果一個協議層只是一條鏈,這是比較扯的,因為實際應用根本做不起來。泡沫是針對加密貨幣的認知,而不是做業務的公司,開發人員應該學區塊鏈應該怎么應用于市場,怎么做業務層,而不要去糾結于你要發一個代幣,發幣這個事實習生兩個小時就能寫了。[2018/3/30]
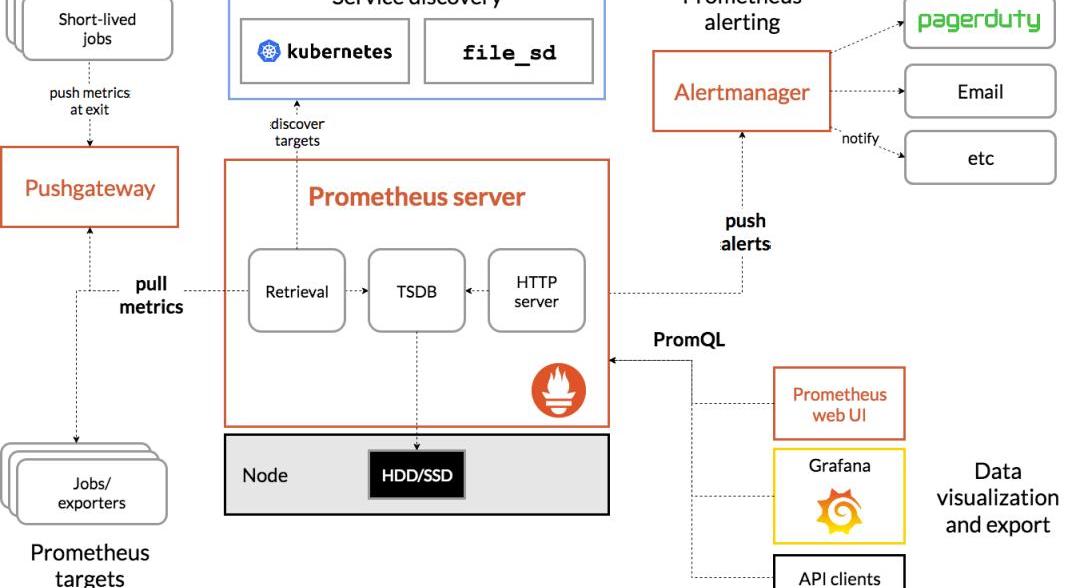
監控工具一般用Prometheus這工具可以監控的內容比較多,其生態如圖(https://prometheus.io/assets/architecture.png)。在測試區塊鏈應用的實踐中,一般是先使用docker-compose部署多個區塊鏈節點模擬正式進行測試的環境,因為正式的測試環境一般硬件配置較高,如果不是自建機房,使用云服務廠商的機器,費用昂貴,這樣做可以節約成本。docker-compose中可以限制容器使用的資源,如內存和CPU算力,甚至綁定CPU核心,對這些資源的監控可以使用cadvisor。為了驗證CPU限制是否準確,可以用stress-ng壓滿核心,看統計結果是否與限制值一致。
中國長城的電源產品涉及區塊鏈領域:中國長城(sz000066)在互動平臺表示,公司電源的產品涉及區塊鏈領域。[2018/3/16]
性能調優
一般遇到性能瓶頸的常見元原因會是網絡、CPU、磁盤IO。引發磁盤IO的瓶頸的操作有寫日志頻頻繁,打印不必要的日志,通過網絡訪問磁盤等。這些資源都會通過系統調用來完成,跟蹤系統調用,可以使用strace來查看執行了哪些系統調用,以及在這些調用上花費的時間等信息還可能遇到的問題是系統不穩定,可以表現為CPU使用率/TPS不穩定。如果在LightLoad區域選擇一定的并發壓力,TPS波動較大的話,可能就是系統設計得不好,需要找到原因和優化了。如果是CPU使用率不穩定,從CPU指令執行層面來看為CPU處于idle狀態的時長參差不齊。這種情況下的原因并不在于有CPU有idle,而是在于處于idle的時間段有長有短。需要借助Linux系統工具、程序對應的profilling工具來觀測,找到原因。分析工具
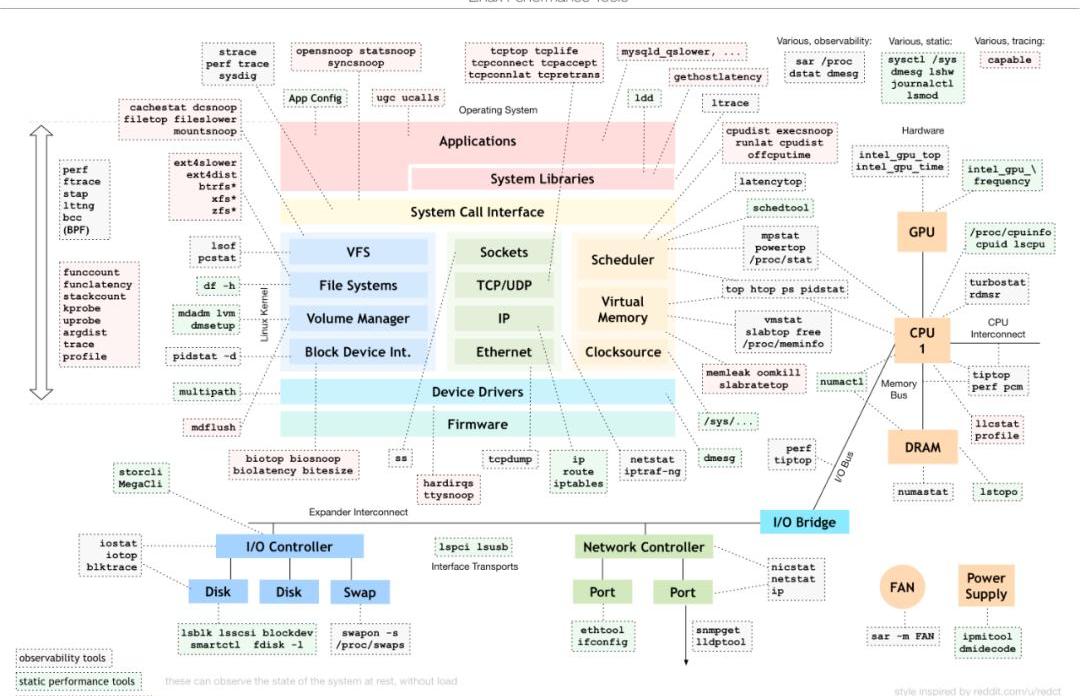
要解決性能問題,首先需要找到原因,尋找原因的分析工具可以參考下圖(https://www.brendangregg.com/Perf/linux_perf_tools_full.png)。這是Linux性能分析最重要的參考資料了,顯示了在不同子系統出現性能問題后,應該用什么樣的工具來觀測和分析。
磁盤IO
磁盤IO一般會導致系統瓶頸,磁盤IO棧比較長,分析起來難度不小。熟悉IO棧,有助于我們發現問題(https://www.thomas-krenn.com/en/wikiEN/images/c/c2/Linux-storage-stack-diagram_v6.2.pdf)
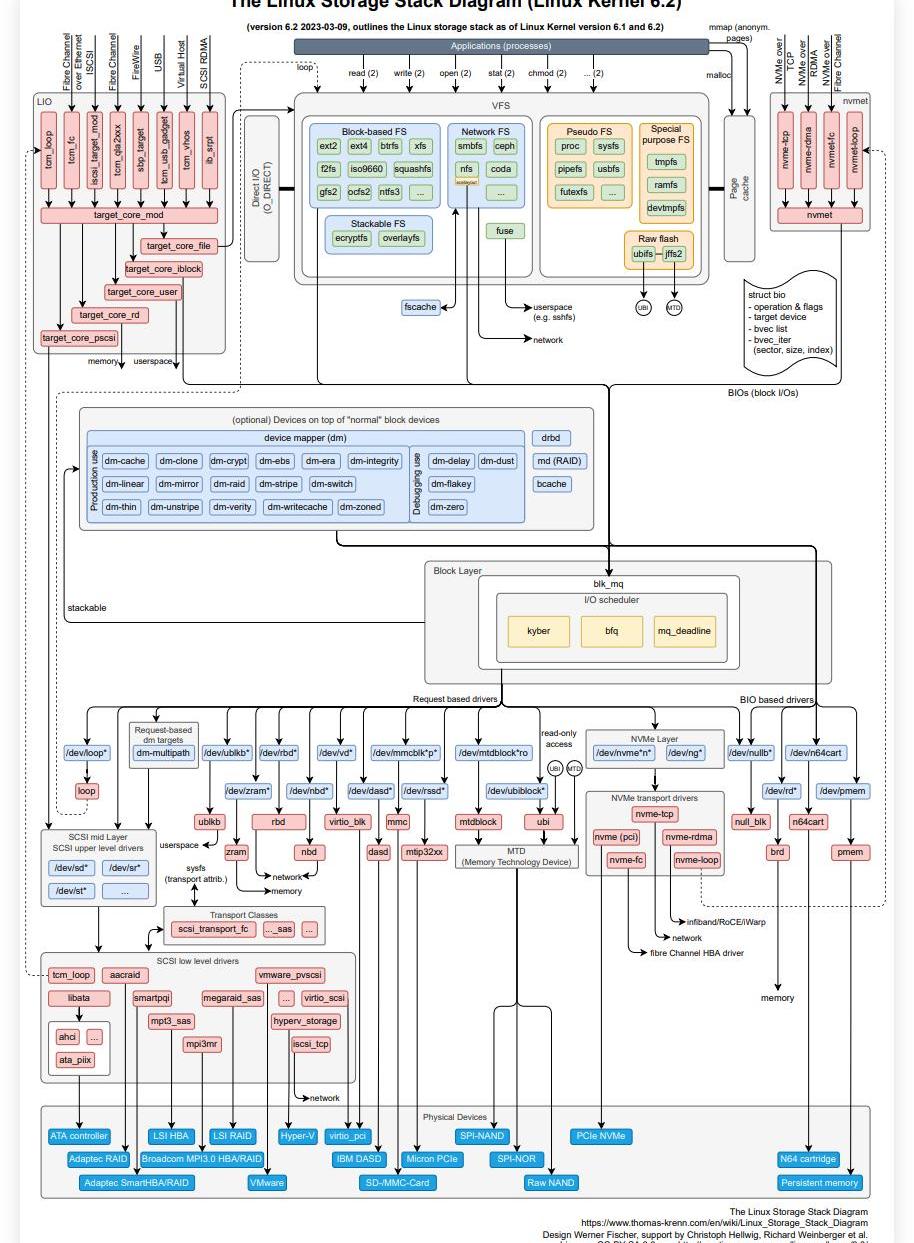
找到原因后,如果能夠通過調整操作系統參數或者應用系統參數優化性能是比較快捷的,如果需要修改代碼,則會涉及系統架構優化,會有涉及和編碼工作,調優周期會很長。下一篇文章將分享使用cosmos-sdk中的SimApp來進行性能測試以及在性能調優方面的方法。
摘要 以太坊將在4月完成上海升級,屆時開放信標鏈質押ETH提款功能。上海升級是以太坊執行層的一次硬分叉,預計共實現9個EIP.
1900/1/1 0:00:00上周,我們發布了LSDFi生態/LSDFiWar報告以及上海升級給LSD帶來的影響的報告,但無論是選擇的項目還是思考的背景都是以太坊。這是因為僅以太坊流動性質押帶來的資金量就超過140億美元.
1900/1/1 0:00:002月27日-3月5日當周,比較值得關注的動態如下:Solana發布改進網絡升級計劃,將組建對抗團隊并改進重啟過程;EOSEVM最終測試網將于3月27日上線.
1900/1/1 0:00:00過去一周突然出現的一連串銀行倒閉,讓許多銀行家想起了2008年金融危機的慘痛回憶。在硅谷銀行于上周五“轟然崩塌”之后,華爾街和其他金融機構試圖弄清問題出在哪里,以及監管機構為何忽視了種種前兆.
1900/1/1 0:00:00加密社區最期待的大事之一--Arbitrum空投--終于來了。ArbitrumFoundation宣布將于3月23日向其社區成員空投ARB治理代幣,并啟動其第3層開發工具ArbitrumOrbi.
1900/1/1 0:00:00近期,Cobo聯合創始人兼CEO神魚接受了新加坡區塊鏈新媒體平臺DeThings專訪。在訪談中,神魚從一個經歷過多輪加密貨幣周期「老韭菜」的視角,分享了對當前市場、FTX事件影響、DeFi創新、.
1900/1/1 0:00:00


